
베이즈의 정리를 이용한 분류 메커니즘
- 나이브 베이즈 분류기는 텍스트 분류를 위해 전통적으로 사용되는 분류기로
인공 신경망 알고리즘에는 속하지 않지만, 머신 러닝 주요 알고리즘으로 분류에 있어 준수한 성능을 보여줌 - 베이즈 정리란 조건부 확률을 계산하는 방법 중 하나로
베이즈 정리를 이용하면 B가 일어나고나서 A가 일어날 확률인 P(B|A)를 쉽게 구할 수 있는 상황이라면 P(A|B)도 구할 수 있음
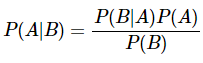
- 나이브 베이즈 분류기는 베이즈 정리를 이용하여 텍스트 분류를 수행하게 됨
- 예) 나이브 베이즈 분류기를 통해서 스팸 메일 필터를 만들 경우
베이즈의 정리에 따라서 입력 텍스트가 정상 메일인지 스팸 메일인지 구분하기 위한 확률을 식으로 표현할 수 있으며
메일의 본문을 단어 토큰화하여 이 단어들을 나이브 베이즈 분류기의 입력으로 사용하게 됨
P(정상 메일|입력 텍스트)가 P(스팸 메일|입력 텍스트)보다 크다면 정상 메일로 볼 수 있고, 반대라면 스팸 메일이라고 볼 수 있음



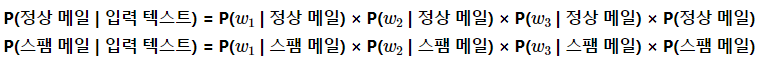
- 나이브 베이즈 분류기에서는 토큰화 이전의 단어의 순서를 중요하지 않고 BoW와 같이 오직 빈도수만을 고려함
스팸 메일 분류기
- 입력 텍스트로부터 해당 텍스트가 정상 메일인지 스팸 메일인지 구분하기
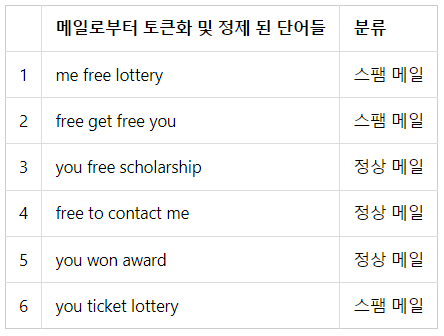
- 'you free lottery'라는 입력 텍스트에 대해서 정상 메일일 확률과 스팸 메일일 확률을 각각 구할 경우 스팸 메일로 분류됨

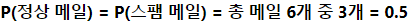

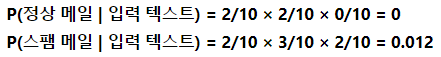
- 'you', 'free', 'lottery'라는 단어가 스팸 메일에서 빈도수가 더 높기 때문에 스팸 메일인 확률이 더 높은 것은 확실하지만
입력 텍스트에 대해서 단, 하나의 단어라도 훈련 텍스트에 없었다면 확률 전체가 0이 되는 것은 지나친 일반화가 됨
이 경우에는 정상 메일에서 'lottery'가 단 한 번도 등장하기 않았고, 그 이유로 정상 메일일 확률 자체가 0%가 되게 됨 - 이를 방지하기 위해서 나이브 베이즈 분류기에서는
각 단어에 대한 확률의 분모, 분자에 전부 숫자를 더해서 분자가 0이 되는 것을 방지하는 라플라스 스무딩을 사용하기도 함
뉴스그룹 데이터 분류하기
- 뉴스그룹 데이터 대한 이해
1) 20개의 다른 주제를 가진 뉴스그룹 데이터의 훈련 데이터를 다운로드
2) 데이터가 어떤 속성으로 구성되어있는지 출력
3) 훈련용 샘플의 개수를 확인
뉴스그룹 데이터는 이미 훈련 데이터와 테스트 데이터를 미리 분류해두었음을 알 수 있음
4) 카테고리 구성 출력
5) 첫 번째 샘플의 카테고리 확인
6) 첫 번재 샘플의 내용 확인
스포츠 카에 대한 글이 0부터 19까지의 카테고리 중 7번 레이블에 속하는 글임을 알 수 있음 - 나이브 베이즈 분류
1) 나이브 베이즈 분류를 사용하기 위해 다운로드 받은 훈련 데이터를 BoW로 만들어 전처리
11314개의 훈련용 샘플의 개수(문서의 수)와 130107개의 전체 훈련 데이터에 등장한 단어의 수를 가진 DTM이 만들어짐
2) TF-IDF 행렬을 생성
DTM을 그래도 나이브 베이즈 분류기에 사용하는 것보다는
TF-IDF 가중치를 적용한 TF-IDF 행렬을 입력으로 텍스트 분류를 수행하면 성능의 개선을 얻을 수 있음
3) 나이브 베이즈 모델을 사용해 라플라스 스무딩을 적용하여 나이브 베이즈 분류를 수행
4) 테스트 데이터를 통한 예측값과 실제값에 대한 정확도 확인
코드
GitHub - GaGa-Kim/ML_Study: 머신러닝 스터디 ⚙
머신러닝 스터디 ⚙. Contribute to GaGa-Kim/ML_Study development by creating an account on GitHub.
github.com
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
베이즈의 정리를 이용한 분류 메커니즘
- 나이브 베이즈 분류기는 텍스트 분류를 위해 전통적으로 사용되는 분류기로
인공 신경망 알고리즘에는 속하지 않지만, 머신 러닝 주요 알고리즘으로 분류에 있어 준수한 성능을 보여줌 - 베이즈 정리란 조건부 확률을 계산하는 방법 중 하나로
베이즈 정리를 이용하면 B가 일어나고나서 A가 일어날 확률인 P(B|A)를 쉽게 구할 수 있는 상황이라면 P(A|B)도 구할 수 있음
- 나이브 베이즈 분류기는 베이즈 정리를 이용하여 텍스트 분류를 수행하게 됨
- 예) 나이브 베이즈 분류기를 통해서 스팸 메일 필터를 만들 경우
베이즈의 정리에 따라서 입력 텍스트가 정상 메일인지 스팸 메일인지 구분하기 위한 확률을 식으로 표현할 수 있으며
메일의 본문을 단어 토큰화하여 이 단어들을 나이브 베이즈 분류기의 입력으로 사용하게 됨
P(정상 메일|입력 텍스트)가 P(스팸 메일|입력 텍스트)보다 크다면 정상 메일로 볼 수 있고, 반대라면 스팸 메일이라고 볼 수 있음
- 나이브 베이즈 분류기에서는 토큰화 이전의 단어의 순서를 중요하지 않고 BoW와 같이 오직 빈도수만을 고려함
스팸 메일 분류기
- 입력 텍스트로부터 해당 텍스트가 정상 메일인지 스팸 메일인지 구분하기
- 'you free lottery'라는 입력 텍스트에 대해서 정상 메일일 확률과 스팸 메일일 확률을 각각 구할 경우 스팸 메일로 분류됨
- 'you', 'free', 'lottery'라는 단어가 스팸 메일에서 빈도수가 더 높기 때문에 스팸 메일인 확률이 더 높은 것은 확실하지만
입력 텍스트에 대해서 단, 하나의 단어라도 훈련 텍스트에 없었다면 확률 전체가 0이 되는 것은 지나친 일반화가 됨
이 경우에는 정상 메일에서 'lottery'가 단 한 번도 등장하기 않았고, 그 이유로 정상 메일일 확률 자체가 0%가 되게 됨 - 이를 방지하기 위해서 나이브 베이즈 분류기에서는
각 단어에 대한 확률의 분모, 분자에 전부 숫자를 더해서 분자가 0이 되는 것을 방지하는 라플라스 스무딩을 사용하기도 함
뉴스그룹 데이터 분류하기
- 뉴스그룹 데이터 대한 이해
1) 20개의 다른 주제를 가진 뉴스그룹 데이터의 훈련 데이터를 다운로드
2) 데이터가 어떤 속성으로 구성되어있는지 출력
3) 훈련용 샘플의 개수를 확인
뉴스그룹 데이터는 이미 훈련 데이터와 테스트 데이터를 미리 분류해두었음을 알 수 있음
4) 카테고리 구성 출력
5) 첫 번째 샘플의 카테고리 확인
6) 첫 번재 샘플의 내용 확인
스포츠 카에 대한 글이 0부터 19까지의 카테고리 중 7번 레이블에 속하는 글임을 알 수 있음 - 나이브 베이즈 분류
1) 나이브 베이즈 분류를 사용하기 위해 다운로드 받은 훈련 데이터를 BoW로 만들어 전처리
11314개의 훈련용 샘플의 개수(문서의 수)와 130107개의 전체 훈련 데이터에 등장한 단어의 수를 가진 DTM이 만들어짐
2) TF-IDF 행렬을 생성
DTM을 그래도 나이브 베이즈 분류기에 사용하는 것보다는
TF-IDF 가중치를 적용한 TF-IDF 행렬을 입력으로 텍스트 분류를 수행하면 성능의 개선을 얻을 수 있음
3) 나이브 베이즈 모델을 사용해 라플라스 스무딩을 적용하여 나이브 베이즈 분류를 수행
4) 테스트 데이터를 통한 예측값과 실제값에 대한 정확도 확인
코드
GitHub - GaGa-Kim/ML_Study: 머신러닝 스터디 ⚙
머신러닝 스터디 ⚙. Contribute to GaGa-Kim/ML_Study development by creating an account on GitHub.
github.com