
태깅 작업
- 각 단어가 어떤 유형에 속해있는지를 알아내는 태깅 작업
- 단어 태깅 작업의 대표적인 두 가지로는
각 단어의 유형이 사람, 장소, 단체 등 어떤 유형인지 알아내는 개체명 인식과
각 단어의 품사가 명사, 동사, 형용사 인지를 알아내는 품사 태깅이 존재 - 개체명 인식기와 품사 태거는 RNN의 다 대 다 작업이면서 앞, 뒤 시점의 입력을 모두 참고하는 양방향 RNN을 사용함
훈련 데이터에 대한 이해
- 태깅 작업은 텍스트 분류 작업과 동일하게 지도 학습에 속함
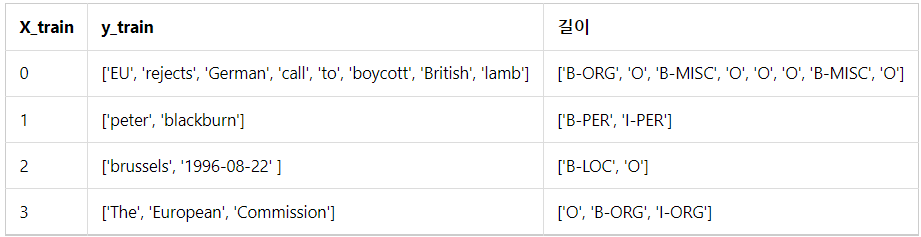
- 태깅을 해야하는 단어 데이터를 X, 레이블에 해당하는 태깅 정보 데이터를 y라고 할 때,
X와 y 데이터의 쌍은 병렬 구조를 가지게 되며 각 데이터의 길이는 같게 됨 - 예1) X_train[3]의 'The'와 y_train[3]의 'O'는 하나의 쌍
예2) X_train[3]의 'European'과 y_train[3]의 'B-ORG'는 하나의 쌍
예3) X_train[3]의 'Commision'과 y_train[3]의 'I-ORG'는 하나의 쌍
- 병렬 관계를 가지는 토큰화가 이루어진 데이터는 정수 인코딩 과정을 거친 후,
모든 데이터의 길이를 동일하게 맞추기 위해 패딩 작업을 거친 후에 딥 러닝 모델의 입력으로 사용됨
시퀀스 레이블링
- 입력 시퀀스 X = [x1, x2, x3, ..., xn]에 대하여
레이블 시퀀스 y = [y1, y2, y3, ..., y4]를 각각 부여하는 작업을 시퀀스 레이블링 작업이라고 함 - 태깅 작업은 대표적인 시퀀스 레이블링 작업
양방향 LSTM
- 이전 시점의 단어 정보 뿐만 아니라 다음 시점의 단어 정보도 참고하므로 양방향 LSTM을 사용하게 됨
- model.add(Bidirectional(LSTM(hidden_units, return_sequences=True)))
RNN의 다-대-다 문제
- RNN의 은닉층은 모든 시점에 대해서 은닉 상태의 값을 출력할 수도 있고(return_sequences=True),
마지막 시점에 대해서만 은닉 상태의 값을 출력할 수도 있음(return_squences=False) - 태깅 작업의 경우에는 다 대 다 문제이므로 출력층에 모든 은닉 상태의 값을 보내도록 함

- 첫 번째 데이터에 해당하는 X_train[0]을 가지고 4번의 시점까지 RNN을 진행했을 경우의 RNN 다 대 다

- 첫 번째 데이터에 해당하는 X_train[0]을 가지고 4번의 시점까지 RNN을 진행했을 경우의 양방향 RNN 다 대 다

양방향 LSTM을 이용한 품사 태깅
- 품사 태깅 데이터에 대한 이해와 전처리
1) NLTK를 이용해 영어 코퍼스에서 토큰화와 품사 태깅 전처리를 진행한 문장 데이터를 받아오기
2) 첫 번째 샘플 출력
품사 태깅 전처리가 수행된 첫 번째 문장이 출력된 것을 볼 수 있음
3) zip() 함수를 이용해서 단어 부분과 품사 태깅 정보 부분을 분리시켜 sentences와 post_tags에 저장
4) 전체 데이터의 길이 분포 확인
5) 케라스 토크나이저를 통해 문장 데이터와 레이블에 해당되는 품사 태깅 정보에 대해 정수 인코딩 진행
6) 단어 집합과 품사 태깅 정보 집합의 크기 확인
7) 정수 인코딩을 수행하여 문장 데이터는 X_train에, 품사 태깅 데이터는 y_train에 저장
8) 대부분의 샘플은 길이가 150 이내이므로 X_train과 y_train의 모든 길이를 임의로 150으로 맞추기
9) 훈련 데이터와 테스트 데이터를 8:2 비율로 분리 - 양방향 LSTM으로 POS Tagger 만들기
1) 임베딩 벡터의 차원과 LSTM의 은닉 상태의 차원을 128로 지정
2) 다 대 다 문제이므로 LSTM의 return_squences의 값은 True로 지정하고 양방향 사용을 위해 Bidirectional() 사용
3) 레이블을 원-핫 인코딩하지 않고 학습을 진행하므로 손실 함수에 sparse_categorical_crossentropy를 사용
4) validation_data로 테스트 데이터를 기재하여 학습 중간에 테스트 데이터의 정확도를 확인
5) 7번의 에포크를 수행
6) 테스트 데이터에 대한 정확도를 측정
7) 정수로부터 단어와 품사 태깅 정보를 리턴하는 index_to_word와 index_to_tag 생성
8) 10번 인덱스 테스트 샘플로부터 실제값과 예측값을 출력
코드
GitHub - GaGa-Kim/ML_Study: 머신러닝 스터디 ⚙
머신러닝 스터디 ⚙. Contribute to GaGa-Kim/ML_Study development by creating an account on GitHub.
github.com
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 12. 태깅 작업 - 개체명 인식 (0) | 2022.12.31 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 11. NLP를 위한 합성곱 신경망 - 문자 임베딩 (0) | 2022.12.29 |
| [딥 러닝을 이용한 자연어 처리 입문] 11. NLP를 위한 합성곱 신경망 - 사전 훈련된 워드 임베딩을 이용한 의도 분류 (0) | 2022.12.29 |
| [딥 러닝을 이용한 자연어 처리 입문] 11. NLP를 위한 합성곱 신경망 - 자연어 처리를 위한 1D CNN (0) | 2022.12.29 |
| [딥 러닝을 이용한 자연어 처리 입문] 11. NLP를 위한 합성곱 신경망 - 합성곱 신경망 (0) | 2022.12.28 |