
4.1) 사라진 SQLEXCEPTION
초난감 예외처리
- JDBC API를 쓰게 될 경우 '처리되지 않은 예외가 있다'고 예외 표시를 해준다.
- 이를 보고 try/catch 블록을 둘러싸주는 것으로 해결하면 컴파일러 에러 메시지도 없어지고 별문제 없이 잘 동작한다.
- 이때 예외가 발생하면 catch 블록을 써서 잡아내는 것까지는 좋지만
아무것도 하지 않고 별문제 없는 것처럼 넘어가 버리는 것은 정말 위험한 일이다. - 결국 발생한 예외로 인해 어떤 기능이 비정상적으로 동작하거나,
메모리나 리소스가 소진되거나, 예상치 못한 문제가 일어난다. - 예외가 발생하면 화면에 출력해주기는 하는 것도 다른 로그나 메시지에 금방 묻혀버리면 놓치기 쉽상이므로
콘솔 로그를 누군가가 계속 모니터링하지 않는 한 이 예외 코드는 심각한 폭탄으로 남아 있을 것이다.
// 초난감 예외처리
try {
...
} catch(SQLException e) {
System.out.println(e);
// e.printStackTree();
}
// 그나마 나은 예외처리
try {
...
} catch(SQLException e) {
e.printStackTree();
System.exit(1);
}- 예외를 처리할 때 반드시 지켜야 할 핵심 원칙은 한 가지다.
- 모든 예외는 적절하게 복구되든지 아니면 작업을 중단시키고 운영자 또는 개발자에게 분명하게 통보돼야 한다.
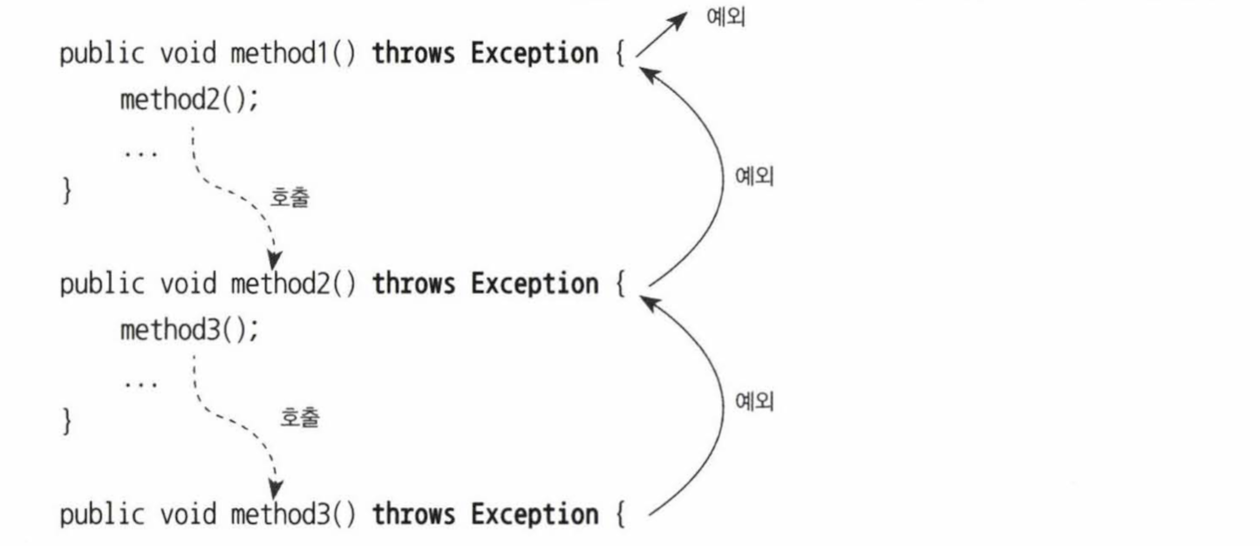
- 예외를 잡아서 뭔가 조치를 취할 방법이 없다면 메소드에 throws SQLException을 선언해서 밖으로 던지고
자신을 호출한 코드에 예외처리 책임을 전가해버려라.
- 무책임한 throws 선언도 심각한 문제점이 있다.
- 매번 정확하게 예외 이름을 적어서 선언하기 귀찮아져 아예 throws Exception이라는,
모든 예외를 던져버리는 선언을 모든 메소드에 기계적으로 넣을 경우, 의미 있는 정보를 얻을 수 없다. - 정말 무엇인가 실행 중에 예외적인 상황이 발생할 수 있다는 것인지, 습관적으로 복사해서 붙여놓은 것인지 알 수 없다.
- 결과적으로 적절한 처리를 통해 복구될 수 있는 예외상황도 제대로 다룰 수 있는 기회를 박탈당한다.
- 매번 정확하게 예외 이름을 적어서 선언하기 귀찮아져 아예 throws Exception이라는,
예외의 종류와 특징
- 자바에서 throws를 통해 발생시킬 수 있는 예외는 크게 세 가지가 있다.
- 첫째는 java.lang.Error 클래스의 서브클래스들이다.
- 에러는 시스템에 뭔가 비정상적인 상황이 발생했을 경우에 사용되며 애플리케이션 코드에서 잡으려고 하면 안 된다.
- 따라서 시스템 레벨에서 특별한 작업을 하는 것이 아니라면 애플리케이션에서는 이 에러에 대한 처리는 신경쓰지 않는다.
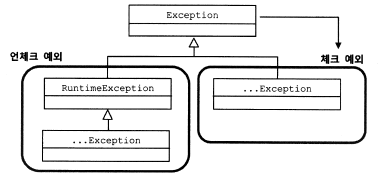
- 둘째는 java.lang.Exception 클래스와 그 서브클래스들로 정의되는 예외들이다.
- 위의 에러와 달리 개발자들이 만든 애플리케이션 코드와 작업 중에 예외상황이 발생했을 경우에 사용된다.
- Exception 클래스는 체크 예외와 언체크 예외로 구분된다.
체크 예외는 Exception 클래스의 서브클래스이면서 RuntimeException 클래스를 상속하지 않는 클래스들이고,
언체크 예외는 Exception 클래스의 서브클래스이면서 RuntimeException 클래스를 상속한 클래스들이다. - 일반적으로 예외라고 하면 Exception 클래스의 서브클래스 중에서 RuntimeException을 상속하지 않는 것만을 말한다.
- 체크 예외가 발생할 수 있는 메소드를 사용할 경우 반드시 예외를 처리하는 코드를 함께 작성해야 한다.
- 셋째는 java.lang.RuntimeException 클래스를 상속하는 예외들이다.
- 이들은 명시적인 예외처리를 강제하지 않으므로 언체크 예외라고 불리며 대표 클래스 이름을 따서 런타임 예외라고도 한다.
- 예외처리를 강제하지는 않지만 명시적으로 잡거나 throws로 선언해줘도 상관없다.
- 런타임 예외는 주로 프로그램의 오류가 있을 때 발생하도록 의도된 것들이다.
- 피할 수 있지만 개발자가 부주의해서 발생할 수 있는 경우에 발생하도록 만든 것이므로
예상하지 못했던 예외상황에서 발생하는 것이 아니기 때문에 예외처리를 하지 않아도 되는 것이다.
예외처리 방법
- 예외를 처리하는 방법에는 세 가지가 있다.
- 첫째는 예외상황을 파악하고 문제를 해결해서 정상 상태로 돌려놓는 것이다. (예외 복구)
- 예외로 인해 기본 작업 흐름이 불가능하면 다른 작업 흐름으로 자연스럽게 유도해주는 것이다.
- 이후 예외가 처리됐으면 비록 기능적으로는 사용자에게 예외상황으로 비쳐도
애플리케이션에서는 정상적으로 설계된 흐름을 따라 진행돼야 한다. - 만약 정해진 횟수만큼 재시도해서 실패했다면 예외 복구는 포기해야 한다.
- 그러므로 예외처리 코드를 강제하는 체크 예외들은 예외를 어떤 식으로든 복구할 가능성이 있는 경우에 사용한다.
int maxretry = MAX_RETRY;
while(maxretry-- > 0) {
try {
...
return;
}
catch(SomeException e) {
// 로그 출력
}
finally {
// 리소스 반납
}
}
throw new RetryFailedException(); // 최대 재시도 횟수를 넘기면 직접 예외 발생- 둘째는 예외처리를 자신이 담당하지 않고 자신을 호출한 쪽으로 던져버리는 것이다. (예외 전달, 예외 회피)
- throws 문으로 선언해서 예외가 발생하면 알아서 던져지게 하거나
catch 문으로 일단 예외를 잡은 후에 로그를 남기고 다시 예외를 던지는 것이다. - 이는 예외를 자신이 처리하지 않고 회피하는 방법이다.
- 하지만 긴밀하게 역할을 분담하고 있는 관계가 아니라면
자신의 코드에서 발생하는 예외를 그냥 던져버리는 건 무책임한 책임회피일 수 있다. - 그러므로 예외를 회피하는 것은 예외를 복구하는 것처럼 의도가 분명해야 한다.
- throws 문으로 선언해서 예외가 발생하면 알아서 던져지게 하거나
public void add() throws SQLException {
// JDBC API
}public void add() throws SQLException {
try {
// JDBC API
}
catch(SQLException e) {
// 로그 출력
throw e;
}
}- 셋째는 예외 전환을 하는 것이다. (예외 전환)
- 예외 회피와 비슷하게 예외를 복구해서 정상적인 상태로는 만들 수 없기 때문에 예외를 메소드 밖으로 던지는 것이다.
- 하지만 예외 회피와 달리, 발생한 예외를 그대로 넘기는 게 아니라 적절한 예외로 전환해서 던진다는 특징이 있다.
- 예외 전환은 내부에서 발생한 예외를 그대로 던지는 것이 그 예외상황에 대한 적절한 의미를 부여해주지 못하는 경우에,
의미를 분명하게 해줄 수 있는 예외로 바꿔주기 위해 사용한다. - 의미가 분명한 예외가 던져지면 서비스 계층 오브젝트에는 적절한 복구 작업을 시도할 수 있다.
- 보통 전환하는 예외에 원래 발생한 예외를 담아서 중첩 예외로 만드는 것이 좋다.
중첩 예외는 새로운 예외를 만들면서 생성자나 initCase() 메소드로 근본 원인이 되는 예외를 넣어준 후,
getCause() 메소드를 이용하면 처음 발생한 예외가 무엇인지 확인할 수 있다. - 뿐만 아니라 예외 전환은 예외를 처리하기 쉽고 단순하게 만들기 위한 포장을 하기 위해 사용한다.
- 이는 의미를 명확하게 하려고 다른 예외로 전환하는 것이 아니라
주로 예외처리를 강제하는 체크 예외가 복구할 수 없을 때, 언체크 예외인 런타임 예외로 바꾸는 경우에 사용한다. - 어차피 복구가 불가능한 예외라면 가능한 한 빨리 런타임 예외로 포장해 던지게 해서
다른 계층의 메소드를 작성할 때 불필요한 throws 선언이 들어가지 않도록 해줘야 한다. - 그리고 예외처리 서비스 등을 이용해 자세한 로그를 남기고, 관리자에게는 메일 등으로 통보해주고,
사용자에게는 친절한 안내 메시지를 보여주는 식으로 처리하는 게 바람직하다.
- 예외 회피와 비슷하게 예외를 복구해서 정상적인 상태로는 만들 수 없기 때문에 예외를 메소드 밖으로 던지는 것이다.
public void add(User user) throws DuplicationUserIdException, SQLException {
try {
// JDBC를 이용해 user 정보를 DB에 추가하는 코드
// 또는 그런 기능을 가진 다른 SQLException을 던지는 메소드를 호출하는 코드
}
catch(SQLException e) {
// ErrorCode가 MySQL의 "Duplicate Entry(1062)"이면 예외 전환
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw DuplicationUserIdException();
// throw DuplicationUserIdException(e);
// throw DuplicationUserException().initCause(e);
else
throw e; // 그 외의 경우는 SQLException 그대로
// throw new RuntimeException(e);
}
}예외처리 전략
- 자바가 처음 만들어질 때 많이 사용되던 애플릿이나 AWT, 스윙을 사용한 독립형 애플리케이션에서는
통제 불가능한 시스템 예외라고 할지라도 애플리케이션의 작업이 중단되지 않게 해주고 상황을 복구해야 한다. - 하지만 자바 엔터프라이즈 서버환경은 다르다.
- 수많은 사용자가 동시에 요청을 보내고 각 요청이 독립적인 작업으로 취급된다.
- 독립형 애플리케이션과 달리 서버의 특정 계층에서 예외가 발생했을 때 작업을 일시 중지하고
사용자와 바로 커뮤니케이션하면서 예외상황을 복구할 수 있는 방법이 없다. - 차라리 애플리케이션 차원에서 예외상황을 미리 파악하고, 예외가 발생하지 않도록 차단하는 게 좋다.
- 예전에는 복구할 가능성이 조금이라고 있다면 체크 예외로 만든다고 생각했는데,
지금은 항상 복구할 수 있는 예외가 아니라면 일단 언체크 예외로 만드는 경향이 있다.
- add() 메소드를 수정해보자.
- add() 메소드는 DuplicateUserIdException과 SQLException 두 가지의 체크 예외를 던지게 되어 있다.
SQLException이 발생할 때 원인이 ID 중복이라면 좀 더 의미 있는 예외인 DuplicateUserIdException으로 전환해준다. - SQLException은 대부분 복구 불가능한 예외이므로 잡아봤자 처리할 것도 없고,
결국 throws를 타고 계속 앞으로 전달되다가 애플리케이션 밖으로 던져질 것이다.
그럴 바에는 그냥 런타임 예외로 포장해 던져버려서 그 밖의 메소드들이 신경 쓰지 않게 해주는 편이 낫다.
아이디 중복 때문에 SQLException이 발생한 경우에는 DuplicateUserIdException이 던지게 하는 코드는 그대로 둔다. - 사용자 아이디가 중복됐을 때 사용하는 DuplicateUserIdException처럼 의미 있는 예외는
add() 메소드를 바로 호출한 오브젝트 대신 더 앞단의 오브젝트에서 다룰 수도 있다.
어디에서든 잡아서 처리할 수 있다면 굳이 체크 예외로 만들지 않고 런타임 예외로 만드는 게 낫다.
그리고 중첩 예외를 만들 수 있도록 생성자를 추가해주도록 한다.
대신 add() 메소드는 명시적으로 DuplicateUserIdException을 던진다고 throws로 선언해야 한다.
- add() 메소드는 DuplicateUserIdException과 SQLException 두 가지의 체크 예외를 던지게 되어 있다.
/**
* 아이디 중복 시 사용하는 예외
*/
public class DuplicateUserIdException extends RuntimeException {
public DuplicateUserIdException(Throwable cause) {
super(cause);
}
}/**
* JdbcTemplate를 적용한 UserDao 클래스
*/
public class UserDao {
private DataSource dataSource;
private JdbcTemplate jdbcTemplate;
// JdbcTemplate 초기화
public void setDataSource(DataSource dataSource) {
// DataSource 오브젝트는 JdbcTemplate을 만든 후에는 사용하지 않으니 저장해두지 않아도 된다.
this.jdbcTemplate = new JdbcTemplate(dataSource);
// SQLException 예외를 위해 사용
this.dataSource = dataSource;
}
// 재사용 가능하도록 독립시킨 RowMapper
private RowMapper<User> userMapper = new RowMapper<User>() {
// ResultSet한 로우의 결과를 오브젝트에 매핑해주는 RowMapper
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
return user;
}
};
/* 새로운 사용자를 생성 */
// JDBC API가 만들어내는 예외를 잡아서 직접 처리하거나, 메소드에 throws를 선언해서 예외가 발생하면 메소드 밖으로 던지게 한다.
public void addWithException(User user) throws DuplicateUserIdException {
Connection c = null;
PreparedStatement ps = null;
try {
// JDBC를 이용해 user 정보를 DB에 추가하는 코드
c = dataSource.getConnection();
ps = c.prepareStatement("insert into users(id, name, password) values(?,?,?)");
ps.setString(1, user.getId());
ps.setString(2, user.getName());
ps.setString(3, user.getPassword());
ps.executeUpdate();
} catch (SQLException e) {
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw new DuplicateUserIdException(e); // 예외 전환
else
throw new RuntimeException(e); // 예외 포장
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (c != null) {
try {
c.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
/* 새로운 사용자를 생성 */
// JdbcTemplate의 update() 메소드를 적용
public void add(final User user) {
this.jdbcTemplate.update("insert into users(id, name, password) values(?,?,?)", user.getId(), user.getName(), user.getPassword());
}
/* 아이디를 가지고 사용자 정보 읽어오기 */
// JdbcTemplate의 queryForObject() 메소드를 적용
public User get(String id) {
return this.jdbcTemplate.queryForObject("select * from users where id = ?", new Object[] {id}, this.userMapper);
}
/* 모든 사용자 정보 읽어오기 */
// JdbcTemplate의 query() 메소드를 적용
public List<User> getAll() {
return this.jdbcTemplate.query("select * from users order by id", this.userMapper);
}
/* 모든 사용자 삭제하기 */
// JdbcTemplate의 update() 메소드를 적용
public void deleteAll() {
this.jdbcTemplate.update("delete from users");
}
/* 사용자 테이블의 레코드 개수 읽어오기 */
// JdbcTemplate의 queryForInt() 메소드를 적용 (Deprecated)
// JdbcTemplate의 queryForObject() 메소드를 적용
public int getCount() {
// return this.jdbcTemplate.queryForInt("select count(*) from users");
return this.jdbcTemplate.queryForObject("select count(*) from users", Integer.class);
}
}- 런타임 예외 중심의 전략은 낙관적인 예외처리 기법이라고 할 수 있다.
- 일단 복구할 수 있는 예외는 없다고 가정한다.
- 예외가 생겨도 어차피 런타임 예외이므로 시스템 레벨에서 알아서 처리해줄 것이고,
꼭 필요한 경우는 런타임 예외라도 잡아서 복구하거나 대응해줄 수 있으니
문제 될 것이 없다는 낙관적인 태도를 기반으로 하고 있다.
- 반면 애플리케이션 예외가 있다.
- 시스템 또는 외부의 예외상황이 원인이 아니라 애플리케이션 자체의 로직에 의해 의도적으로 발생시키고,
반드시 catch 해서 무엇인가 조치를 취하도록 요구하는 예외이다. - 이를 위해 리턴 값으로 결과를 확인하고, 예외상황을 체크할 수 있다.
- 하지만 예외상황에 대한 리턴 값을 명확하게 코드화하고 잘 관리하지 않으면 혼란이 생길 수 있다.
- 일관된 예외상황에서 결과 값에 대한 정책이 완벽하게 갖춰져 있고, 사전에 상수로 정의해둔 표준 코드를 사용하지 않는다면
자칫 개발자 사이의 의사소통 문제로 인해 제대로 동작하지 않을 위험이 있다. - 또한 if 문 같이 결과 값을 확인하는 조건문이 자주 등장하여 코드가 지저분해지고 흐름을 파악하고 이해하기 힘들어진다.
- 다른 방법으로는 정상적인 흐름을 따르는 코드는 그대로 두고, 예외 상황에만 비즈니스적 의미를 띈 예외를 던지도록 한다.
- 이때는 예외가 발생할 수 있는 코드를 try 블록 안에 깔끔하게 정리해두고 예외상황에 대한 처리는 catch 블록에 모으므로
코드를 이해하기 편하고 번거로운 if 문을 남발하지 않아도 된다. - 이때 사용하는 예외는 의도적으로 체크 예외로 만들어
개발자가 잊지 않고 자주 발생 가능한 예외상황에 대한 로직을 구현하도록 강제해주는 게 좋다.
- 시스템 또는 외부의 예외상황이 원인이 아니라 애플리케이션 자체의 로직에 의해 의도적으로 발생시키고,
try {
BigDecimal balance = account.withdraw(amount);
...
// 정상적인 처리 결과를 출력하도록 진행
}
catch(InsufficientBalanceException e) { // 체크 예외
// InsufficientBalanceException에 담긴 인출 가능한 잔고금액 정보를 가져옴
BigDecimal availFunds = e.getAvailFunds();
...
// 잔고 부족 안내 메시지를 준비하고 이를 출력하도록 진행
}SQLException은 어떻게 됐나?
- 앞서 JdbcContext로 만들었던 코드를 스프링의 JdbcTemplate을 적용하도록 바꾸면서 모든 SQLException이 사라졌다.
- 99%의 SQLException은 코드 레벨에서 복구할 방법이 없다.
프로그램의 오류 또는 개발자의 부주의(SQL 문법, 제약조건 위반, DB 서버 다운, 네트워크 불안정, 꽉찬 DB 커넥션 풀)
때문에 발생하는 경우이거나, 통제할 수 없는 외부상황 때문에 발생한 것이다. - 시스템의 예외라면 당연히 애플리케이션 레벨에서 복구할 방법이 없으므로
관리자나 개발자에게 빨리 예외가 발생했다는 사실을 알려지도록 전달하는 방법밖에는 없다. - 따라서 예외처리 전략을 적용하여 필요도 없는 throws 선언이 등장하도록 방치하지 말고
가능한 빨리 언체크/런타임 예외로 전환해줘야 한다. - 스프링의 JdbcTemplate은 예외처리 전략을 따르고 있으므로 JdbcTemplate 템플릿과 콜백 안에서 발생하는
모든 SQLException을 런타임 예외인 DataAccessException으로 포장해서 던져준다. - 따라서 JdbcTemplate을 사용하는 UserDao 메소드에선 꼭 필요한 경우에만
런타임 예외인 DataAccessException을 잡아서 처리하면 되고 그 외의 경우에는 무시해도 된다.
그러므로 DAO 메소드에서 SQLException이 모두 사라진 것이다. - 그 밖에도 스프링의 API 메소드에 정의되어 있는 대부분의 예외는 런타임 예외이므로
발생 가능한 예외가 있다고 하더라도 이를 처리하도록 강제하지 않는다.
- 99%의 SQLException은 코드 레벨에서 복구할 방법이 없다.
public int update(final String sql) throws DataAccessException { ... }
public int update(String sql, @Nullable Object... args) throws org.springframework.dao.DataAccessException { ... }/**
* JdbcTemplate를 적용한 UserDao 클래스
*/
public class UserDao {
private JdbcTemplate jdbcTemplate;
// JdbcTemplate 초기화
public void setDataSource(DataSource dataSource) {
// DataSource 오브젝트는 JdbcTemplate을 만든 후에는 사용하지 않으니 저장해두지 않아도 된다.
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// 재사용 가능하도록 독립시킨 RowMapper
private RowMapper<User> userMapper = new RowMapper<User>() {
// ResultSet한 로우의 결과를 오브젝트에 매핑해주는 RowMapper
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
return user;
}
};
/* 새로운 사용자를 생성 */
// JdbcTemplate의 update() 메소드를 적용
// 스프링의 JdbcTemplate은 예외처리 전략을 따르고 있으므로
// JdbcTemplate 템플릿과 콜백 안에서 발생하는 모든 SQLException을 런타임 예외인 DataAccessException으로 포장해서 던져준다.
public void add(final User user) {
this.jdbcTemplate.update("insert into users(id, name, password) values(?,?,?)", user.getId(), user.getName(), user.getPassword());
}
/* 아이디를 가지고 사용자 정보 읽어오기 */
// JdbcTemplate의 queryForObject() 메소드를 적용
public User get(String id) {
return this.jdbcTemplate.queryForObject("select * from users where id = ?", new Object[] {id}, this.userMapper);
}
/* 모든 사용자 정보 읽어오기 */
// JdbcTemplate의 query() 메소드를 적용
public List<User> getAll() {
return this.jdbcTemplate.query("select * from users order by id", this.userMapper);
}
/* 모든 사용자 삭제하기 */
// JdbcTemplate의 update() 메소드를 적용
public void deleteAll() {
this.jdbcTemplate.update("delete from users");
}
/* 사용자 테이블의 레코드 개수 읽어오기 */
// JdbcTemplate의 queryForInt() 메소드를 적용 (Deprecated)
// JdbcTemplate의 queryForObject() 메소드를 적용
public int getCount() {
// return this.jdbcTemplate.queryForInt("select count(*) from users");
return this.jdbcTemplate.queryForObject("select count(*) from users", Integer.class);
}
}
'Java-Spring > 토비의 스프링 3.1' 카테고리의 다른 글
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 서비스 추상화 (0) (0) | 2023.11.30 |
|---|---|
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 예외 (2) (0) | 2023.09.30 |
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 예외 (0) (0) | 2023.09.30 |
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 템플릿 (6) (0) | 2023.09.29 |
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 템플릿 (5) (0) | 2023.09.29 |
4.1) 사라진 SQLEXCEPTION
초난감 예외처리
- JDBC API를 쓰게 될 경우 '처리되지 않은 예외가 있다'고 예외 표시를 해준다.
- 이를 보고 try/catch 블록을 둘러싸주는 것으로 해결하면 컴파일러 에러 메시지도 없어지고 별문제 없이 잘 동작한다.
- 이때 예외가 발생하면 catch 블록을 써서 잡아내는 것까지는 좋지만
아무것도 하지 않고 별문제 없는 것처럼 넘어가 버리는 것은 정말 위험한 일이다. - 결국 발생한 예외로 인해 어떤 기능이 비정상적으로 동작하거나,
메모리나 리소스가 소진되거나, 예상치 못한 문제가 일어난다. - 예외가 발생하면 화면에 출력해주기는 하는 것도 다른 로그나 메시지에 금방 묻혀버리면 놓치기 쉽상이므로
콘솔 로그를 누군가가 계속 모니터링하지 않는 한 이 예외 코드는 심각한 폭탄으로 남아 있을 것이다.
// 초난감 예외처리
try {
...
} catch(SQLException e) {
System.out.println(e);
// e.printStackTree();
}
// 그나마 나은 예외처리
try {
...
} catch(SQLException e) {
e.printStackTree();
System.exit(1);
}- 예외를 처리할 때 반드시 지켜야 할 핵심 원칙은 한 가지다.
- 모든 예외는 적절하게 복구되든지 아니면 작업을 중단시키고 운영자 또는 개발자에게 분명하게 통보돼야 한다.
- 예외를 잡아서 뭔가 조치를 취할 방법이 없다면 메소드에 throws SQLException을 선언해서 밖으로 던지고
자신을 호출한 코드에 예외처리 책임을 전가해버려라.
- 무책임한 throws 선언도 심각한 문제점이 있다.
- 매번 정확하게 예외 이름을 적어서 선언하기 귀찮아져 아예 throws Exception이라는,
모든 예외를 던져버리는 선언을 모든 메소드에 기계적으로 넣을 경우, 의미 있는 정보를 얻을 수 없다. - 정말 무엇인가 실행 중에 예외적인 상황이 발생할 수 있다는 것인지, 습관적으로 복사해서 붙여놓은 것인지 알 수 없다.
- 결과적으로 적절한 처리를 통해 복구될 수 있는 예외상황도 제대로 다룰 수 있는 기회를 박탈당한다.
- 매번 정확하게 예외 이름을 적어서 선언하기 귀찮아져 아예 throws Exception이라는,
예외의 종류와 특징
- 자바에서 throws를 통해 발생시킬 수 있는 예외는 크게 세 가지가 있다.
- 첫째는 java.lang.Error 클래스의 서브클래스들이다.
- 에러는 시스템에 뭔가 비정상적인 상황이 발생했을 경우에 사용되며 애플리케이션 코드에서 잡으려고 하면 안 된다.
- 따라서 시스템 레벨에서 특별한 작업을 하는 것이 아니라면 애플리케이션에서는 이 에러에 대한 처리는 신경쓰지 않는다.
- 둘째는 java.lang.Exception 클래스와 그 서브클래스들로 정의되는 예외들이다.
- 위의 에러와 달리 개발자들이 만든 애플리케이션 코드와 작업 중에 예외상황이 발생했을 경우에 사용된다.
- Exception 클래스는 체크 예외와 언체크 예외로 구분된다.
체크 예외는 Exception 클래스의 서브클래스이면서 RuntimeException 클래스를 상속하지 않는 클래스들이고,
언체크 예외는 Exception 클래스의 서브클래스이면서 RuntimeException 클래스를 상속한 클래스들이다. - 일반적으로 예외라고 하면 Exception 클래스의 서브클래스 중에서 RuntimeException을 상속하지 않는 것만을 말한다.
- 체크 예외가 발생할 수 있는 메소드를 사용할 경우 반드시 예외를 처리하는 코드를 함께 작성해야 한다.
- 셋째는 java.lang.RuntimeException 클래스를 상속하는 예외들이다.
- 이들은 명시적인 예외처리를 강제하지 않으므로 언체크 예외라고 불리며 대표 클래스 이름을 따서 런타임 예외라고도 한다.
- 예외처리를 강제하지는 않지만 명시적으로 잡거나 throws로 선언해줘도 상관없다.
- 런타임 예외는 주로 프로그램의 오류가 있을 때 발생하도록 의도된 것들이다.
- 피할 수 있지만 개발자가 부주의해서 발생할 수 있는 경우에 발생하도록 만든 것이므로
예상하지 못했던 예외상황에서 발생하는 것이 아니기 때문에 예외처리를 하지 않아도 되는 것이다.
예외처리 방법
- 예외를 처리하는 방법에는 세 가지가 있다.
- 첫째는 예외상황을 파악하고 문제를 해결해서 정상 상태로 돌려놓는 것이다. (예외 복구)
- 예외로 인해 기본 작업 흐름이 불가능하면 다른 작업 흐름으로 자연스럽게 유도해주는 것이다.
- 이후 예외가 처리됐으면 비록 기능적으로는 사용자에게 예외상황으로 비쳐도
애플리케이션에서는 정상적으로 설계된 흐름을 따라 진행돼야 한다. - 만약 정해진 횟수만큼 재시도해서 실패했다면 예외 복구는 포기해야 한다.
- 그러므로 예외처리 코드를 강제하는 체크 예외들은 예외를 어떤 식으로든 복구할 가능성이 있는 경우에 사용한다.
int maxretry = MAX_RETRY;
while(maxretry-- > 0) {
try {
...
return;
}
catch(SomeException e) {
// 로그 출력
}
finally {
// 리소스 반납
}
}
throw new RetryFailedException(); // 최대 재시도 횟수를 넘기면 직접 예외 발생- 둘째는 예외처리를 자신이 담당하지 않고 자신을 호출한 쪽으로 던져버리는 것이다. (예외 전달, 예외 회피)
- throws 문으로 선언해서 예외가 발생하면 알아서 던져지게 하거나
catch 문으로 일단 예외를 잡은 후에 로그를 남기고 다시 예외를 던지는 것이다. - 이는 예외를 자신이 처리하지 않고 회피하는 방법이다.
- 하지만 긴밀하게 역할을 분담하고 있는 관계가 아니라면
자신의 코드에서 발생하는 예외를 그냥 던져버리는 건 무책임한 책임회피일 수 있다. - 그러므로 예외를 회피하는 것은 예외를 복구하는 것처럼 의도가 분명해야 한다.
- throws 문으로 선언해서 예외가 발생하면 알아서 던져지게 하거나
public void add() throws SQLException {
// JDBC API
}public void add() throws SQLException {
try {
// JDBC API
}
catch(SQLException e) {
// 로그 출력
throw e;
}
}- 셋째는 예외 전환을 하는 것이다. (예외 전환)
- 예외 회피와 비슷하게 예외를 복구해서 정상적인 상태로는 만들 수 없기 때문에 예외를 메소드 밖으로 던지는 것이다.
- 하지만 예외 회피와 달리, 발생한 예외를 그대로 넘기는 게 아니라 적절한 예외로 전환해서 던진다는 특징이 있다.
- 예외 전환은 내부에서 발생한 예외를 그대로 던지는 것이 그 예외상황에 대한 적절한 의미를 부여해주지 못하는 경우에,
의미를 분명하게 해줄 수 있는 예외로 바꿔주기 위해 사용한다. - 의미가 분명한 예외가 던져지면 서비스 계층 오브젝트에는 적절한 복구 작업을 시도할 수 있다.
- 보통 전환하는 예외에 원래 발생한 예외를 담아서 중첩 예외로 만드는 것이 좋다.
중첩 예외는 새로운 예외를 만들면서 생성자나 initCase() 메소드로 근본 원인이 되는 예외를 넣어준 후,
getCause() 메소드를 이용하면 처음 발생한 예외가 무엇인지 확인할 수 있다. - 뿐만 아니라 예외 전환은 예외를 처리하기 쉽고 단순하게 만들기 위한 포장을 하기 위해 사용한다.
- 이는 의미를 명확하게 하려고 다른 예외로 전환하는 것이 아니라
주로 예외처리를 강제하는 체크 예외가 복구할 수 없을 때, 언체크 예외인 런타임 예외로 바꾸는 경우에 사용한다. - 어차피 복구가 불가능한 예외라면 가능한 한 빨리 런타임 예외로 포장해 던지게 해서
다른 계층의 메소드를 작성할 때 불필요한 throws 선언이 들어가지 않도록 해줘야 한다. - 그리고 예외처리 서비스 등을 이용해 자세한 로그를 남기고, 관리자에게는 메일 등으로 통보해주고,
사용자에게는 친절한 안내 메시지를 보여주는 식으로 처리하는 게 바람직하다.
- 예외 회피와 비슷하게 예외를 복구해서 정상적인 상태로는 만들 수 없기 때문에 예외를 메소드 밖으로 던지는 것이다.
public void add(User user) throws DuplicationUserIdException, SQLException {
try {
// JDBC를 이용해 user 정보를 DB에 추가하는 코드
// 또는 그런 기능을 가진 다른 SQLException을 던지는 메소드를 호출하는 코드
}
catch(SQLException e) {
// ErrorCode가 MySQL의 "Duplicate Entry(1062)"이면 예외 전환
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw DuplicationUserIdException();
// throw DuplicationUserIdException(e);
// throw DuplicationUserException().initCause(e);
else
throw e; // 그 외의 경우는 SQLException 그대로
// throw new RuntimeException(e);
}
}예외처리 전략
- 자바가 처음 만들어질 때 많이 사용되던 애플릿이나 AWT, 스윙을 사용한 독립형 애플리케이션에서는
통제 불가능한 시스템 예외라고 할지라도 애플리케이션의 작업이 중단되지 않게 해주고 상황을 복구해야 한다. - 하지만 자바 엔터프라이즈 서버환경은 다르다.
- 수많은 사용자가 동시에 요청을 보내고 각 요청이 독립적인 작업으로 취급된다.
- 독립형 애플리케이션과 달리 서버의 특정 계층에서 예외가 발생했을 때 작업을 일시 중지하고
사용자와 바로 커뮤니케이션하면서 예외상황을 복구할 수 있는 방법이 없다. - 차라리 애플리케이션 차원에서 예외상황을 미리 파악하고, 예외가 발생하지 않도록 차단하는 게 좋다.
- 예전에는 복구할 가능성이 조금이라고 있다면 체크 예외로 만든다고 생각했는데,
지금은 항상 복구할 수 있는 예외가 아니라면 일단 언체크 예외로 만드는 경향이 있다.
- add() 메소드를 수정해보자.
- add() 메소드는 DuplicateUserIdException과 SQLException 두 가지의 체크 예외를 던지게 되어 있다.
SQLException이 발생할 때 원인이 ID 중복이라면 좀 더 의미 있는 예외인 DuplicateUserIdException으로 전환해준다. - SQLException은 대부분 복구 불가능한 예외이므로 잡아봤자 처리할 것도 없고,
결국 throws를 타고 계속 앞으로 전달되다가 애플리케이션 밖으로 던져질 것이다.
그럴 바에는 그냥 런타임 예외로 포장해 던져버려서 그 밖의 메소드들이 신경 쓰지 않게 해주는 편이 낫다.
아이디 중복 때문에 SQLException이 발생한 경우에는 DuplicateUserIdException이 던지게 하는 코드는 그대로 둔다. - 사용자 아이디가 중복됐을 때 사용하는 DuplicateUserIdException처럼 의미 있는 예외는
add() 메소드를 바로 호출한 오브젝트 대신 더 앞단의 오브젝트에서 다룰 수도 있다.
어디에서든 잡아서 처리할 수 있다면 굳이 체크 예외로 만들지 않고 런타임 예외로 만드는 게 낫다.
그리고 중첩 예외를 만들 수 있도록 생성자를 추가해주도록 한다.
대신 add() 메소드는 명시적으로 DuplicateUserIdException을 던진다고 throws로 선언해야 한다.
- add() 메소드는 DuplicateUserIdException과 SQLException 두 가지의 체크 예외를 던지게 되어 있다.
/**
* 아이디 중복 시 사용하는 예외
*/
public class DuplicateUserIdException extends RuntimeException {
public DuplicateUserIdException(Throwable cause) {
super(cause);
}
}/**
* JdbcTemplate를 적용한 UserDao 클래스
*/
public class UserDao {
private DataSource dataSource;
private JdbcTemplate jdbcTemplate;
// JdbcTemplate 초기화
public void setDataSource(DataSource dataSource) {
// DataSource 오브젝트는 JdbcTemplate을 만든 후에는 사용하지 않으니 저장해두지 않아도 된다.
this.jdbcTemplate = new JdbcTemplate(dataSource);
// SQLException 예외를 위해 사용
this.dataSource = dataSource;
}
// 재사용 가능하도록 독립시킨 RowMapper
private RowMapper<User> userMapper = new RowMapper<User>() {
// ResultSet한 로우의 결과를 오브젝트에 매핑해주는 RowMapper
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
return user;
}
};
/* 새로운 사용자를 생성 */
// JDBC API가 만들어내는 예외를 잡아서 직접 처리하거나, 메소드에 throws를 선언해서 예외가 발생하면 메소드 밖으로 던지게 한다.
public void addWithException(User user) throws DuplicateUserIdException {
Connection c = null;
PreparedStatement ps = null;
try {
// JDBC를 이용해 user 정보를 DB에 추가하는 코드
c = dataSource.getConnection();
ps = c.prepareStatement("insert into users(id, name, password) values(?,?,?)");
ps.setString(1, user.getId());
ps.setString(2, user.getName());
ps.setString(3, user.getPassword());
ps.executeUpdate();
} catch (SQLException e) {
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw new DuplicateUserIdException(e); // 예외 전환
else
throw new RuntimeException(e); // 예외 포장
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (c != null) {
try {
c.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
/* 새로운 사용자를 생성 */
// JdbcTemplate의 update() 메소드를 적용
public void add(final User user) {
this.jdbcTemplate.update("insert into users(id, name, password) values(?,?,?)", user.getId(), user.getName(), user.getPassword());
}
/* 아이디를 가지고 사용자 정보 읽어오기 */
// JdbcTemplate의 queryForObject() 메소드를 적용
public User get(String id) {
return this.jdbcTemplate.queryForObject("select * from users where id = ?", new Object[] {id}, this.userMapper);
}
/* 모든 사용자 정보 읽어오기 */
// JdbcTemplate의 query() 메소드를 적용
public List<User> getAll() {
return this.jdbcTemplate.query("select * from users order by id", this.userMapper);
}
/* 모든 사용자 삭제하기 */
// JdbcTemplate의 update() 메소드를 적용
public void deleteAll() {
this.jdbcTemplate.update("delete from users");
}
/* 사용자 테이블의 레코드 개수 읽어오기 */
// JdbcTemplate의 queryForInt() 메소드를 적용 (Deprecated)
// JdbcTemplate의 queryForObject() 메소드를 적용
public int getCount() {
// return this.jdbcTemplate.queryForInt("select count(*) from users");
return this.jdbcTemplate.queryForObject("select count(*) from users", Integer.class);
}
}- 런타임 예외 중심의 전략은 낙관적인 예외처리 기법이라고 할 수 있다.
- 일단 복구할 수 있는 예외는 없다고 가정한다.
- 예외가 생겨도 어차피 런타임 예외이므로 시스템 레벨에서 알아서 처리해줄 것이고,
꼭 필요한 경우는 런타임 예외라도 잡아서 복구하거나 대응해줄 수 있으니
문제 될 것이 없다는 낙관적인 태도를 기반으로 하고 있다.
- 반면 애플리케이션 예외가 있다.
- 시스템 또는 외부의 예외상황이 원인이 아니라 애플리케이션 자체의 로직에 의해 의도적으로 발생시키고,
반드시 catch 해서 무엇인가 조치를 취하도록 요구하는 예외이다. - 이를 위해 리턴 값으로 결과를 확인하고, 예외상황을 체크할 수 있다.
- 하지만 예외상황에 대한 리턴 값을 명확하게 코드화하고 잘 관리하지 않으면 혼란이 생길 수 있다.
- 일관된 예외상황에서 결과 값에 대한 정책이 완벽하게 갖춰져 있고, 사전에 상수로 정의해둔 표준 코드를 사용하지 않는다면
자칫 개발자 사이의 의사소통 문제로 인해 제대로 동작하지 않을 위험이 있다. - 또한 if 문 같이 결과 값을 확인하는 조건문이 자주 등장하여 코드가 지저분해지고 흐름을 파악하고 이해하기 힘들어진다.
- 다른 방법으로는 정상적인 흐름을 따르는 코드는 그대로 두고, 예외 상황에만 비즈니스적 의미를 띈 예외를 던지도록 한다.
- 이때는 예외가 발생할 수 있는 코드를 try 블록 안에 깔끔하게 정리해두고 예외상황에 대한 처리는 catch 블록에 모으므로
코드를 이해하기 편하고 번거로운 if 문을 남발하지 않아도 된다. - 이때 사용하는 예외는 의도적으로 체크 예외로 만들어
개발자가 잊지 않고 자주 발생 가능한 예외상황에 대한 로직을 구현하도록 강제해주는 게 좋다.
- 시스템 또는 외부의 예외상황이 원인이 아니라 애플리케이션 자체의 로직에 의해 의도적으로 발생시키고,
try {
BigDecimal balance = account.withdraw(amount);
...
// 정상적인 처리 결과를 출력하도록 진행
}
catch(InsufficientBalanceException e) { // 체크 예외
// InsufficientBalanceException에 담긴 인출 가능한 잔고금액 정보를 가져옴
BigDecimal availFunds = e.getAvailFunds();
...
// 잔고 부족 안내 메시지를 준비하고 이를 출력하도록 진행
}SQLException은 어떻게 됐나?
- 앞서 JdbcContext로 만들었던 코드를 스프링의 JdbcTemplate을 적용하도록 바꾸면서 모든 SQLException이 사라졌다.
- 99%의 SQLException은 코드 레벨에서 복구할 방법이 없다.
프로그램의 오류 또는 개발자의 부주의(SQL 문법, 제약조건 위반, DB 서버 다운, 네트워크 불안정, 꽉찬 DB 커넥션 풀)
때문에 발생하는 경우이거나, 통제할 수 없는 외부상황 때문에 발생한 것이다. - 시스템의 예외라면 당연히 애플리케이션 레벨에서 복구할 방법이 없으므로
관리자나 개발자에게 빨리 예외가 발생했다는 사실을 알려지도록 전달하는 방법밖에는 없다. - 따라서 예외처리 전략을 적용하여 필요도 없는 throws 선언이 등장하도록 방치하지 말고
가능한 빨리 언체크/런타임 예외로 전환해줘야 한다. - 스프링의 JdbcTemplate은 예외처리 전략을 따르고 있으므로 JdbcTemplate 템플릿과 콜백 안에서 발생하는
모든 SQLException을 런타임 예외인 DataAccessException으로 포장해서 던져준다. - 따라서 JdbcTemplate을 사용하는 UserDao 메소드에선 꼭 필요한 경우에만
런타임 예외인 DataAccessException을 잡아서 처리하면 되고 그 외의 경우에는 무시해도 된다.
그러므로 DAO 메소드에서 SQLException이 모두 사라진 것이다. - 그 밖에도 스프링의 API 메소드에 정의되어 있는 대부분의 예외는 런타임 예외이므로
발생 가능한 예외가 있다고 하더라도 이를 처리하도록 강제하지 않는다.
- 99%의 SQLException은 코드 레벨에서 복구할 방법이 없다.
public int update(final String sql) throws DataAccessException { ... }
public int update(String sql, @Nullable Object... args) throws org.springframework.dao.DataAccessException { ... }/**
* JdbcTemplate를 적용한 UserDao 클래스
*/
public class UserDao {
private JdbcTemplate jdbcTemplate;
// JdbcTemplate 초기화
public void setDataSource(DataSource dataSource) {
// DataSource 오브젝트는 JdbcTemplate을 만든 후에는 사용하지 않으니 저장해두지 않아도 된다.
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// 재사용 가능하도록 독립시킨 RowMapper
private RowMapper<User> userMapper = new RowMapper<User>() {
// ResultSet한 로우의 결과를 오브젝트에 매핑해주는 RowMapper
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
return user;
}
};
/* 새로운 사용자를 생성 */
// JdbcTemplate의 update() 메소드를 적용
// 스프링의 JdbcTemplate은 예외처리 전략을 따르고 있으므로
// JdbcTemplate 템플릿과 콜백 안에서 발생하는 모든 SQLException을 런타임 예외인 DataAccessException으로 포장해서 던져준다.
public void add(final User user) {
this.jdbcTemplate.update("insert into users(id, name, password) values(?,?,?)", user.getId(), user.getName(), user.getPassword());
}
/* 아이디를 가지고 사용자 정보 읽어오기 */
// JdbcTemplate의 queryForObject() 메소드를 적용
public User get(String id) {
return this.jdbcTemplate.queryForObject("select * from users where id = ?", new Object[] {id}, this.userMapper);
}
/* 모든 사용자 정보 읽어오기 */
// JdbcTemplate의 query() 메소드를 적용
public List<User> getAll() {
return this.jdbcTemplate.query("select * from users order by id", this.userMapper);
}
/* 모든 사용자 삭제하기 */
// JdbcTemplate의 update() 메소드를 적용
public void deleteAll() {
this.jdbcTemplate.update("delete from users");
}
/* 사용자 테이블의 레코드 개수 읽어오기 */
// JdbcTemplate의 queryForInt() 메소드를 적용 (Deprecated)
// JdbcTemplate의 queryForObject() 메소드를 적용
public int getCount() {
// return this.jdbcTemplate.queryForInt("select count(*) from users");
return this.jdbcTemplate.queryForObject("select count(*) from users", Integer.class);
}
}
'Java-Spring > 토비의 스프링 3.1' 카테고리의 다른 글
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 서비스 추상화 (0) (0) | 2023.11.30 |
|---|---|
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 예외 (2) (0) | 2023.09.30 |
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 예외 (0) (0) | 2023.09.30 |
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 템플릿 (6) (0) | 2023.09.29 |
| [토비의 스프링 3.1] Vol.1 스프링의 이해와 원리 - 템플릿 (5) (0) | 2023.09.29 |