✔️ 인덱스
인덱스란?
- RDBMS에서 검색 속도를 높이기 위한 기술로 테이블의 칼럼을 색인화하여 따로 파일로 저장함
- 칼럼의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들게 됨
- 해당 테이블의 레코드를 전체 탐색(Full Scan) 하지 않고, 색인화된 인덱스 파일 검색으로 인해 검색 속도가 향상됨
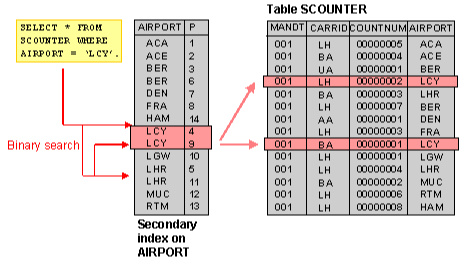
- 반면 인덱스 생성 시, 파일의 크기가 증가하고 한 페이지를 동시에 수정할 수 있는 병행성이 줄어들게 됨
또한 데이터 변경 작업이 자주 일어나는 경우, 인덱스를 재작성해야 하므로
인덱스 된 필드에서 데이터를 업데이트하거나, 레코드를 추가 또는 삭제 시 성능이 떨어짐 - 그러므로 Where 절에서 자주 사용되는 컬럼,칼럼, 외래키가 사용되는 칼럼, 조인에 자주 사용되는 칼럼의 경우 인덱스를 사용하고,
데이터 중복도가 높은 컬럼이나 DML(INSERT, DELETE, UPDATE)이 자주 일어나는 칼럼에는 인덱스를 사용하지 않도록 함 - 인덱스를 설정할 때는 인덱스를 설정하는 필드의 속성도 중요하므로 SELECT 질의를 어떻게 할 것인가에 따라
인덱스를 어떻게 생성할 것인가에 대해 많은 영향을 끼치게 됨 - 클러스터드 인덱스는 테이블의 프라이머리 키에 대해서
프라이머리 키 값이 비슷한 레코드까지 묶어서 저장할 수 있으며 테이블 당 한 개만 생성할 수 있음
이에 반해 Non 클러스터드 인덱스는 테이블 당 여러 개 생성할 수 있음
인덱스의 자료구조
- 테이블을 생성하면, MYD, MYI, FRM 3개의 파일이 생성됨
- MYD : 실제 데이터가 들어가 있는 파일
- MYI : 인덱스 정보가 들어가 있는 파일
- FRM : 테이블 구조가 저장되어 있는 파일
- 인덱스를 사용하지 않는 경우, MYI 파일이 비어져 있지만 인덱싱하는 경우 MYI 파일이 생성되고
이후에 사용자가 SELECT 쿼리로 인덱스를 사용하는 컬럼을 탐색 시, 테이블이 아닌 MYI 파일의 내용을 검색하게 됨 - DBMS에서는 인덱스를 B+-Tree, Hash 인덱스 알고리즘으로 관리하게 됨
- B+-Tree 인덱스 알고리즘
일반적으로 사용되는 인덱스 알고리즘, 컬럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱 - Hash 인덱스 알고리즘
칼럼의 값으로 해시 값을 계산해서 인덱싱하는 알고리즘으로 매우 빠른 검색을 지원
하지만 동등 연산(=)만 가능하므로 부등호 연산 사용 시 문제가 발생함
주로 메모리 기반의 데이터베이스에서 많이 사용
- B+-Tree 인덱스 알고리즘
'Tech Interview > Database' 카테고리의 다른 글
| [Database] 정규화 (0) | 2024.01.03 |
|---|---|
| [Database] 이상 (0) | 2024.01.02 |
| [Database] 조인 (0) | 2023.12.29 |
| [Database] 키 (0) | 2023.12.28 |
| [Database] 데이터베이스 (0) | 2023.12.27 |
✔️ 인덱스
인덱스란?
- RDBMS에서 검색 속도를 높이기 위한 기술로 테이블의 칼럼을 색인화하여 따로 파일로 저장함
- 칼럼의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들게 됨
- 해당 테이블의 레코드를 전체 탐색(Full Scan) 하지 않고, 색인화된 인덱스 파일 검색으로 인해 검색 속도가 향상됨
- 반면 인덱스 생성 시, 파일의 크기가 증가하고 한 페이지를 동시에 수정할 수 있는 병행성이 줄어들게 됨
또한 데이터 변경 작업이 자주 일어나는 경우, 인덱스를 재작성해야 하므로
인덱스 된 필드에서 데이터를 업데이트하거나, 레코드를 추가 또는 삭제 시 성능이 떨어짐 - 그러므로 Where 절에서 자주 사용되는 컬럼,칼럼, 외래키가 사용되는 칼럼, 조인에 자주 사용되는 칼럼의 경우 인덱스를 사용하고,
데이터 중복도가 높은 컬럼이나 DML(INSERT, DELETE, UPDATE)이 자주 일어나는 칼럼에는 인덱스를 사용하지 않도록 함 - 인덱스를 설정할 때는 인덱스를 설정하는 필드의 속성도 중요하므로 SELECT 질의를 어떻게 할 것인가에 따라
인덱스를 어떻게 생성할 것인가에 대해 많은 영향을 끼치게 됨 - 클러스터드 인덱스는 테이블의 프라이머리 키에 대해서
프라이머리 키 값이 비슷한 레코드까지 묶어서 저장할 수 있으며 테이블 당 한 개만 생성할 수 있음
이에 반해 Non 클러스터드 인덱스는 테이블 당 여러 개 생성할 수 있음
인덱스의 자료구조
- 테이블을 생성하면, MYD, MYI, FRM 3개의 파일이 생성됨
- MYD : 실제 데이터가 들어가 있는 파일
- MYI : 인덱스 정보가 들어가 있는 파일
- FRM : 테이블 구조가 저장되어 있는 파일
- 인덱스를 사용하지 않는 경우, MYI 파일이 비어져 있지만 인덱싱하는 경우 MYI 파일이 생성되고
이후에 사용자가 SELECT 쿼리로 인덱스를 사용하는 컬럼을 탐색 시, 테이블이 아닌 MYI 파일의 내용을 검색하게 됨 - DBMS에서는 인덱스를 B+-Tree, Hash 인덱스 알고리즘으로 관리하게 됨
- B+-Tree 인덱스 알고리즘
일반적으로 사용되는 인덱스 알고리즘, 컬럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱 - Hash 인덱스 알고리즘
칼럼의 값으로 해시 값을 계산해서 인덱싱하는 알고리즘으로 매우 빠른 검색을 지원
하지만 동등 연산(=)만 가능하므로 부등호 연산 사용 시 문제가 발생함
주로 메모리 기반의 데이터베이스에서 많이 사용
- B+-Tree 인덱스 알고리즘
'Tech Interview > Database' 카테고리의 다른 글
| [Database] 정규화 (0) | 2024.01.03 |
|---|---|
| [Database] 이상 (0) | 2024.01.02 |
| [Database] 조인 (0) | 2023.12.29 |
| [Database] 키 (0) | 2023.12.28 |
| [Database] 데이터베이스 (0) | 2023.12.27 |