
S3 – Baseline Performance
- S3는 자동으로 아주 많은 수의 요청을 처리하도록 스케일링이 가능하며
S3에서 첫 바이트를 얻기까지 100-200ms 정도의 굉장히 짧은 지연시간 소요
즉 이는 접두어 및 초 당 3500개의 PUT/COPY/POST/DELETE 요청을 처리하며
접두어 및 초 당 5500개의 GET/HEAD 요청을 버킷 내에서 처리하는 속도의 아주 고성능 - 버킷 내의 접두어(prefix)의 개수에는 제한이 없음
- 예) file이라는 이름의 객체 4개를 통해 해당 객체의 접두어를 분석
- bucket/folder1/sub1/file => /folder1/sub1/
bucket 내에 folder1/sub1/file이 존재하며 접두어는 bucket과 file 사이의 뭐든 될 수 있음
이 file에 대한 접두어는 초당 3500개의 PUT과 5500개의 GET을 얻을 수 있음 - bucket/folder1/sub2/file => /folder1/sub2/
접두어는 bucket과 file 사이의 뭐든 될 수 있음
이 file에 대한 접두어는 초당 3500개의 PUT과 5500개의 GET을 얻을 수 있음 - bucket/1/file => /1/
접두어는 bucket과 file 사이의 뭐든 될 수 있음
이 file에 대한 접두어는 초당 3500개의 PUT과 5500개의 GET을 얻을 수 있음 - bucket/2/file => /2/
접두어는 bucket과 file 사이의 뭐든 될 수 있음
이 file에 대한 접두어는 초당 3500개의 PUT과 5500개의 GET을 얻을 수 있음
이 위의 4개의 접두어에 읽기 작업을 균일하게 분산시키면 초당 22000개의 HEAD와 GET 요청을 수행할 수 있어 좋음
- bucket/folder1/sub1/file => /folder1/sub1/
S3 – KMS Limitation
- S3의 성능 제한
- SSE-KMS를 사용해 객체를 KMS 암호화하는 경우 KMS 제한에 의해 영향을 받을 수 있음
- 파일을 업로드하면 KMS 제한이 S3에서 GenerateDataKey KMS API를 호출할 것이고
SSE-KMS를 통해 S3에서 파일을 다운로드하는 경우에는 Decrypt KMS API를 호출하게 됨
위 두 가지 요청은 KMS 할당량에 집계가 됨 - 예) SSE-KMS 암호화를 사용해 파일을 업로드/다운로드하는 상황
S3 버킷이 API를 호출하고 키를 생성하거나 KMS 키로 해독해 그로부터 결과를 가져옴

- KMS는 기본적으로 초당 요청에 대한 할당량을 가지고 있음 (리전에 따라 초당 5500개 또는 10000개, 300000개)
만약 더 많은 양이 필요한 경우 서비스 할당량 콘솔을 통해 할당량 증가를 요청할 수 있음 - 만약 초당 10000개 이상의 요청이 초당 5500개의 요청을 지원하는 특정 리전에 발생하면 요청이 지나치게 몰리므로
KMS가 S3의 성능을 방해하지 않게끔 파일이 아주 많거나 S3 버킷을 많이 쓸 때 주의
S3 Performance
- S3 성능 최적화를 위한 방법
- 분할 업로드 (Multi-Part upload)
100MB가 넘는 파일은 분할 업로드가 권장되며 5GB가 넘는다면 분할 업로드가 필수
분할 업로드는 병렬화를 통해 전송 속도를 높이고 대역폭을 극대화
예) 파일을 작은 덩어리의 여러 파트로 나눠서 각 파일을 S3에 병렬로 업로드한 후 모든 파트가 업로드되면 다시 모아 합침
- 전송 가속 (S3 Transfer Acceleration)
업로드와 다운로드를 위한 것으로 파일을 AWS의 엣지 로케이션으로 전송함으로써 전송 속도를 높임
엣지 로케이션에서는 데이터를 대상 리전의 S3 버킷으로 보내줌
전송 가속은 분할 업로드와 호환됨
예) 파일이 미국에 있는 상태에서 호주에 있는 S3 버킷에 파일을 업로드하려고 할 때
파일을 미국에 있는 엣지 로케이션에 업로드하게 되면 공용 인터넷을 통해 아주 빠르게 처리하여
엣지 로케이션에서 호주의 S3 버킷으로 고속 사설 AWS 네트워크를 통해 파일이 전송하므로
공용 인터넷을 최소한으로 거치면서 사설 AWS 네트워크의 사용을 최대화
S3 Performance – S3 Byte-Range Fetches
- 파일을 가장 효율적으로 읽는 법
- S3 바이트 범위 가져오기 방법을 이용해 파일의 특정 바이트 범위를 얻어 GET을 마비시키는 방식
바이트 범위를 얻는데 실패한 경우에는 작은 바이트 범위를 얻는 작업을 다시 시도함으로써 실패에 대한 복원성을 가짐
예) S3에 아주 큰 파일이 있을 때 파일의 첫 몇 바이트에 해당하는 파트를 요청할 때 나머지 파트는 두 번째 파트, 세 번째 파트
... 으로 마지막 파트까지 존재하며 모든 파트들에 대해 특정 바이트 범위 가져오기를 요청
이 때 바이트 범위라고 불리는건 파일의 특정 범위만을 요청하는 것이므로 이 요청은 전부 병렬적으로 이루어짐
그렇기 때문에 GET을 병렬화해서 다운로드를 가속화할 수 있는 것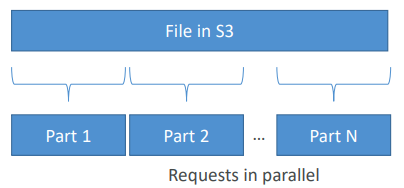
- 파일의 일부를 회수하는 방법
S3에 있는 파일의 첫 50바이트가 파일에 대한 정보를 제공하는 헤더라는 사실을 알고 있다면 헤더 요청을 바로 보내 정보를 얻음
'Cloud > AWS' 카테고리의 다른 글
| [SAA] S3 이벤트 알림 (0) | 2022.03.28 |
|---|---|
| [SAA] S3 셀렉트 & Glacier Select (0) | 2022.03.28 |
| [SAA] S3 애널리틱스 (0) | 2022.03.28 |
| [SAA] S3 수명 주기 규칙 (0) | 2022.03.28 |
| [SAA] S3 스토리지 클래스 + Glacier (0) | 2022.03.27 |