막 생성되자마자 분석 또는 처리를 위해 애플리케이션으로 보내진 실시간 데이터를 사용하며 이 데이터에는 애플리케이션 로그와 지표, 웹사이트 클릭 스트림, IoT 원격 측정 데이터 등이 존재
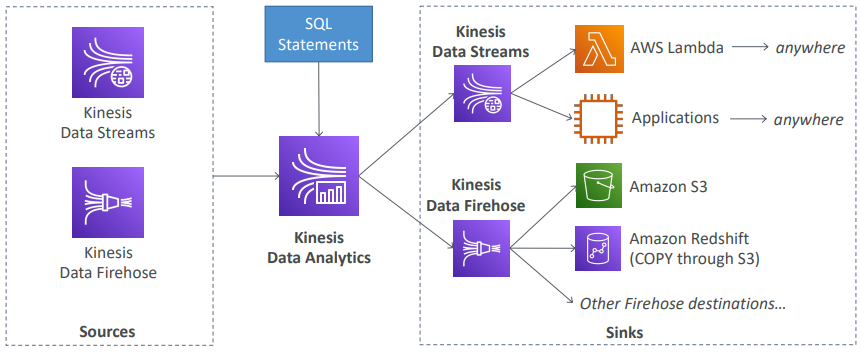
Kinesis에는 4가지 요소가 존재 1) Kinesis Data Streams : 데이터 스트림을 캡처, 처리, 저장 2) Kinesis Data Firehose : 데이터 스트림을 AWS 데이터 스토어로 불러옴 3) Kinesis Data Analytics : SQL이나 Apache Flink로 데이터 스트림을 분석 4) Kinesis Video Stream : 동영상 스트림을 캡처, 처리, 저장
Kinesis Data Streams
Kinesis Data Streams 내부 스트림이 있으며 스트림은 샤드로 구성되며 번호가 붙음 시간이 지나면 샤드 개수를 스케일링할 수 있으며, 샤드가 많이 있을수록 스트림을 통과하도록 허용되는 처리량이 더 늘어나게 됨 각 샤드는 초당 1MB를 제공하거나 각 샤드가 초당 1000 메시지를 제공 얘) 샤드가 30개라면 초당 30MB를 갖게 되거나 초당 30000 메시지를 갖게됨
Producers Kinesis Data Steams에 데이터 만들기 위해 다양한 생산자가 있어야 하며 이는 애플리케이션일 수도 있고 모바일 및 데스크톱 클라이언트일 수도 있음 이들은 내부적으로 SDK를 사용하거나 KPL(Kinesis Producers Library)를 사용 또는 Kinesis Agent를 통해 Kinesis Data Steams로 데이터를 전송 모든 종류의 애플리케이션이 데이터를 실시간으로 스트림에 전송 가능하며, 애플리케이션이 스트림으로 레코드를 보내면 레코드는 파티션 키로 구성되고 최대 1MB의 데이터 블랍이 됨 이런 레코드를 생성한 후에 Kinesis Data Steams으로 전송
Consumers Kinesis Data Steams에서 데이터를 소비하며 이들은 KCL(Kinesis Client Library)나 SDK를 사용하는 애플리케이션이며 또는 람다함수, Kinesis Data Firehose, Kinesis Data Analytics일 수도 있음 소비자가 받게 되는 레코드에는 동일한 파티션 키와 시퀀스 번호가 있으며 데이터 블랍도 존재하며 Pub/Sub 패턴이 존재 소비 메커니즘에는 두 가지 종류가 있으며 1) 공유 소비 메커니즘을 사용하면 모든 소비자 애플리케이션에 걸쳐 샤드마다 초당 2MB를 얻게 됨 2) 향상된 소비자 메커니즘을 사용하면 각 소비자마다 샤드마다 초당 2MB를 얻게 되며 비싸지만 처리량이 훨씬 많아짐
Kinesis Data Steams은 프로비저닝된 샤드마다 과금되며 샤드는 원하는 만큼 가질 수 있음
Kinesis Data Steams의 데이터는 기본값인 1일에서 최대 365일까지 보존되므로 소비자의 데이터를 재처리하고 재생할 수 있는 능력이 존재
Kinesis Data Steams에 데이터가 삽입되면 삭제되지 않는 불변성을 가짐
같은 파티션을 공유하는 데이터는 같은 샤드로 이동
Kinesis Data Firehose
Producers 대상 목적지에 데이터를 저장하기 위한 것으로 다양한 애플리케이션이 데이터를 직접 Kinesis Data Firehose로 전송하거나 또는 데이터를 Kinesis Data Steams, CloudWatch, AWS IoT에서 읽을 수 있음
Kinesis Data Firehose 가장 일반적인 형태는 Kinesis Data Steams으로부터 Firehose가 읽기를 하는 것이며 레코드를 하나씩 읽을 때 한 번에 최대 1MB를 읽을 수 있으며 레코드를 변환하고 싶으면 람다함수를 이용 Kinesis Data Firehose는 커다란 데이터 배치를 채워서 대상 데이터베이스나 대상 목적지로 데이터 쓰기를 시도하며 이를 배치 쓰기라고 하며 이는 즉석에서 쓰기를 하지 않고 효율적으로 쓰기 위해 일괄적으로 처리하는 것을 뜻함
Destinations 그러므로 Kinesis Data Firehose를 준 실시간 서비스라고 하면 목적지 측에는 AWS가 존재 만약 AWS의 RedShift로 쓰기를 하려면 Firehose가 먼저 S3에 쓰기를 하고 RedShift로 COPY 명령을 내려야 함 이외에 타사 목적지를 포함한 기타 목적지로는 Datadog, Splunk New Relic, MongoDB가 있음 또는 API로 유효한 HTTP 엔드 포인트가 있자면 사용자 지정 목적지로 데이터를 전달할 수 있음
All or Failed Data Firehose로 이동하는 모든 데이터를 아카이브하려면 모든 데이터 혹은 실패한 데이터를 Kinesis Data Firehose에서 백업 S3 버킷으로 보낼 수 있음
Firehose는 완전 관리형 서비스이기 때문에 관리할 것이 없고 자동 스케일링이 가능하며 서버리스
Firehose를 통과하는 데이터에 대해서만 과금
미리 Firehose를 프로비저닝할 필요가 없으며 준 실시간으로 작동하며 배치가 가득 차지 않은 경우(처리량이 충분치 않거나 최소 32MB의 데이터가 없다면) 최소 60초 정도의 지연 시간이 존재
Firehose는 다양한 데이터 형식, 전환, 변환, 압축을 지원 AWS Lamda 함수를 통해 사용자 지정 데이터 변환을 지원
모든 실패한 데이터 혹은 모든 데이터를 전부 백업 S3 버킷에 보낼 수 있음
Kinesis Data Streams vs Firehose
Data Steams은 데이터를 규모에 맞게 수집하는 스트리밍 서비스로 사용자 지정 코드를 작성하여 스트림에서 데이터를 보내고 소비하며 지연시간이 약 200ms초라서 거의 실시간에 가까우며 사용자가 직접 스케일링을 관리 샤드 추가는 샤드 분할이라 부르고 샤드 제거는 새드 병합이라고 부름 데이터 스토리지는 KDS(Kinesis Data Steams)에 보존되며 기간은 1일에서 365일으로 재실행 기능을 지원
Firehose는 사용자가 직접 데이터를 목적지로 불러오며 목적지에는 S3, RedShift, ElasticSearch, 타사, HTTP가 존재 완전 관리형이며 버퍼가 있고 데이터를 배치로 묶어서 쓰기 때문에 준 실시간 서비스임 스케일링은 자동화되어 있으며 데이터 스토리지가 없어서 데이터를 재실행할 수 없음
Kinesis Data Analytics (SQL application)
SQL 애플리케이션을 위한 것으로 SQL 코드를 스트림에 쓰려면 Kinesis Data Analytics를 통해서 소스에서 읽기를 해야 함 소스에는 Kinesis Data Steams이나 Kinesis Data Firehose가 있음
사용자 고유의 SQL 문장 쓰기로 실시간으로 데이터를 처리하며 실시간으로 목적지에 쿼리 결과를 보낼 수 있음 목적지로는 Kinesis Data Steams, Kinesis Data Firehose가 될 수 있음 그리고 그 후 Firehose는 S3, RedShift, 혹은 다른 목적지로 보낼 수 있음 또한 만약 Kinesis Data Steams로 데이터를 보내랴먄 사용자가 람다 함수 사용을 위해 자체 애플리케이션을 작성하거나 혹은 데이터를 실시간으로 처리하기 위해 EC2에서 실행되는 자체 애플리케이션을 작성함
Kinesis Data Analytics는 Kinesis Steams에서 SQL을 이용해 실시간 분석을 하며 완전 관리형이라서 프로비저닝할 서버가 없고 스케일링은 자동화되어 있으며 실시간 분석을 수행
KDA(Kinesis Data Analytics)를 통과하는 실제 데이터 흐름에 따라 비용이 청구되므로 실제 소비율을 반영
실시간 쿼리에서 스트림을 생성할 수 있음
타임시리즈 분석, 실시간 대시보드, 실시간 지표에 이를 사용
<Kinesis Data Streams 실습>
Kinesis Data Streams 생성 데이터 스트림을 생성하고 이름을 test로 설정한 후 원하는 샤드의 수를 입력 샤드 측정 도구로 원하는 샤드의 수를 측정할 수 있으며 이번 실습은 최소량으로 샤드를 하나만으로 하여 데이터 스트림 생성 허용되는 용량은 초당 1MB의 쓰기와 최대 초당 1000개까지의 데이터 레코드가 허용되며 읽기는 샤드마다 초당 2MB까지 허용 만약 샤드를 10으로 늘리면 전부 10배가 됨
Kinesis Data Steams 생성 확인 데이터 보존 기간을 보면 현재 1일로 설정되어 있는데 변경이 가능하며 Applications에서 생산자와 소비자를 설정할 수 있음 생산자로는 Amazon Kinesis Agent, SDK, Kinesis Producer Library를 사용하여 데이터를 생산하게 할 수 잇음 소비자 측면에서는 Kinesis Data Analystics, Kinesis Data Firehose, Kinesis Client Library가 있음
모니터링 측면에서는 스트림 지표를 얻을 수 있어 Get에 레코드가 얼마나 있는지를 보여주며 데이터를 총 얼마나 수신했는지 등을 보여줌 또한 지연 시간이 있지는 않은지 성공 및 오류도 알 수 있고 읽기와 쓰기에 대한 처리량을 초과했는지도 알 수 있음
구성에서는 샤드 용량을 변경할 수 있어 원하는 만큼 샤드를 추가 또는 제거할 수 있음 암호화에서는 서버 측 암호화를 활성화할 수 있고 데이터 보존도 활성화할 수 있어 최대 265일까지 보존 설정 가능 그리고 지표를 더 원할 경우 향상된 샤드 레벨 지표도 얻을 수 있으며 향상된 팬아웃을 구성할 수도 있음
모니터링구성
CLI를 사용해 Kinesis Data Streams에 데이터를 나타내기 CloudShell을 사용해 CLI를 시작하면 리전의 자격 증명을 통해 구성이 됨
데이터를 생산하고 싶으면 aws kinesis put-record --stream-name ~에 파티션 키와 데이터 내용인 'user signup' 입력 이를 보내면 base 63로 변환이되며 응답으로 샤드 ID를 얻게 되며 메시지의 시퀀스 번호도 얻게 됨 이를 세 번 반복하여 Kinesis Data Streams에 세 개의 메시지를 전송
이제 Kinesis Data Streams에서 메시지를 읽고 싶다면 샤드명을 얻어야 함 이를 위한 명령어로 aws kinesis describe-stream --stream-name test를 입력하여 샤드명과 ID, 그리고 다른 정보들을 얻음 그리고 샤드 ID를 입력한 명령어를 통해 샤드 반복자를 얻은 후 이를 붙여 넣어 명령어를 입력하면 조금 전 보낸 레코드가 나타남 하지만 Kinesis에 레코드가 도착하면 데이터는 읽을 수 없는 이상한 텍스트 블랍으로 표시되며 이는 base 64로 인코딩된 것 이 데이터가 맞는 데이터인지 확인하기 위해서는 인터넷을 통해 디코딩을 해야 하며 이를 디코드하면 'user signup'이 나옴
그러므로 이제 Kinesis 데이터 스트림에서 생성과 소비를 할 수 있음을 알 수 있음
전체 명렁어 코드스트림으로 데이터를 생산샤드명 얻기샤드 반복자 얻기보냈던 레코드 읽기인터넷을 통한 디코드
Kinesis Data Firehose 생성 create delivery stream을 누르면 도식이 나와 데이터 파이어호스의 작동을 보여줌 이는 여러 곳에서 온 데이터를 수집하는데 데이터 생산자는 Kinesis 데이터 스트림이 될 수 있고 Kinesis Agent, AWS 서비스들, SDK API를 사용해 커스텀 앱에 하는 Direct PUT일 수도 있음 마지막으로 데이터가 대상 서비스로 로드되는데 대상(목적지) 서비스란 S3, OpenSearch, Redshift, 다양한 HTTP 엔드 포인트
이제 Kinesis Data Firehose를 생성하기 위해 소스로 Kinesis Data Stream을 선택한 후 목적지는 S3로 설정
소스 셋팅으로는 데이터 스트림 ARN을 선택해야 하므로 위에서 만든 Kinesis 데이터 스트림의 이름인 test를 선택
레코드를 변형 및 변환하고 싶다면 선택적으로 가능하며 Lambda를 이용해 레코드 변형도 가능
목적지를 S3로 설정했으므로 이를 위한 S3 버킷인 demo-firehose-stephane-v3를 생성한 후 대상 셋팅에서 설정
버퍼의 힌트가 존재하는데 버퍼란 Kinesis Data Firehose가 S3에 데이터를 얼마나 빨리 전달하는가를 뜻하며 기본 버퍼 크기는 5MB, 간격은 300초이므로 버퍼가 5MB 크기에 달하거나 300초에 도달하면 S3로 플러시됨을 뜻함 신속하게 하기 위해 버퍼 크기를 1MB, 간격은 60초로 설정하여 60초마다 버펀 안에 뭐가 있는지에 상관없이 S3로 전달 버퍼의 사이즈가 더 크거나 버퍼 간격이 더 길면 더 효율적이지만 지연시간이 길어지도 지연도 늘어나게 됨
압축과 암호는 S3 버킷에 데이터를 저장할 때 더 최적화된 옵션이며 GZIP, Snappy, Zip, Hadoop-Compatible Snappy 존재 또한 암호화를 통해 레코드의 암호화 설정 가능
이외에도 CloudWatch 오류 로깅 등으로 많은 최적화 옵션을 가짐
또한 Firehose 전송 스트림이 S3에 입력값을 넣도록 액세스할 수 있는지 확인하기 위해 Kinesis Data Firehose 서비스에 의해 자동으로 IAM 역할이 생성됨
도식소스, 목적지 설정소스 설정레코드를 변형 및 변환대상(목적지) 설정버퍼의 힌트압축과 암호화
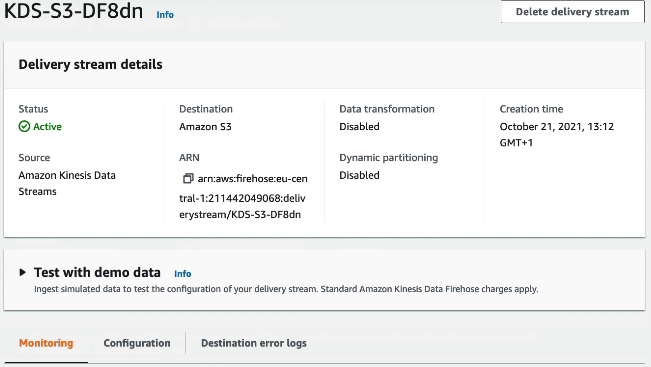
Kinesis Data Firehose 생성 확인 모든 구성이 나와있으며 모니터링에 들어가면 지표들에 의해 얼마나 많은 데이터가 Firehose 전송 스트림을 통해 움직이는지 보여줌
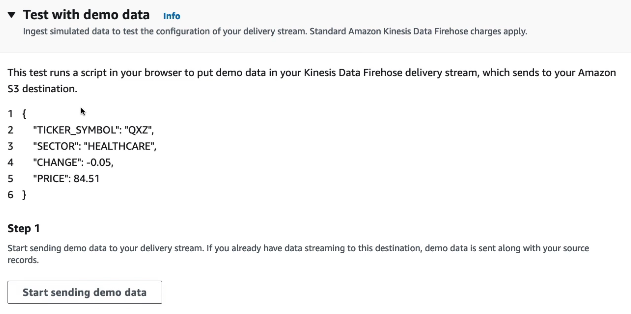
에러 로그의 목적지를 살펴보게 되면 사용 가능한 CloudWatch 로그가 나오며 데모 데이터를 테스트할 수 있고 전송 시작 가능
하지만 Kinesis Data Firehose는 Kinesis Data Streams에 후크되어 있기 때문에 이 대신에 CloudShell을 이용해 스트림으로 위와 동일한 3개의 데이터(user signup, user login, user logout)를 직접 전송
이 후 Kinesis Data Firehose에는 버퍼가 있기 때문에 60초를 기다린 후 새로고침을 하게 되면 S3 버킷에 객체가 생성됨 효율성을 위해 하나의 파일로 배치 처리된 텍스트 파일을 열게 되면 user signup user login user logout을 볼 수 있으므로 Kinesis Data Streams으로 데이터들이 다 보내진 후 Firehose를 통해 S3로 보내진 것을 알 수 있음