
Amazon EMR
- Elastic MapReduce로 MapReduce는 빅데이터 용어이므로 EMR은 빅데이터에 사용되는 Hadoop 클러스터를 생성
그러므로 EMR은 Hadoop 프레임워크를 제공하며 클러스터를 생성하고 데이터를 업로드할 수 있음
+) S3에서도 업로드됨 - 빅데이터는 많은 양의 데이터인 페타바이트, 테라바이트 정도를 분석 및 처리하는데 사용
- EMR에서 생성하는 클러스터는 수백 개의 EC2 인스턴스로 구성될 수 있음
- EMR은 인스턴스들이 동시에 작동할 수 있게 조정하고 구성할 수 있음
- EMR을 통해 Hadoop 클러스터 구성을 한 후,
우리는 단지 Spart, HBase, Presto, Flink 등의 엔진을 사용해 데이터를 분석하고 처리만 함 - EMR은 모든 것을 프로비저닝하고 모든 것을 구성
- EMR과 작동하는 오토 스케일링이 존재하며 스팟 인스턴스로 통합되어 있으므로
빅데이터 분석 비용을 절감하고 싶다면 스팟 인스턴스를 사용 - 클러스터 상태를 모니터링할 수 있으며 처리 진행 상황 또한 볼 수 있으며 S3에서 처리 결과를 볼 수 있음
- 데이터 처리, 머신 러닝, 웹 인덱싱, 빅데이터 등에 사용
<EMR 실습>
- EMR 클러스터 생성
EMR은 Hadoop 프레임워크를 제공하며 클러스터를 생성하고 데이터를 업로드할 수 있으며 S3에서도 업로드할 수 있음
이후 입력한 모든 정보를 생성하고 클러스터 상태를 모니터링할 수 있으며 처리 진행 상황을 볼 수 있음
또한 S3에서도 처리 결과를 볼 수 있음
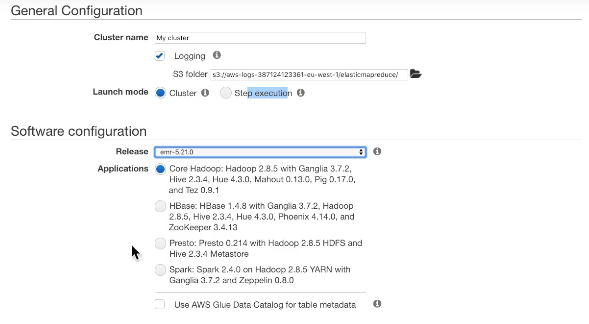
클러스터를 생성하려면 클러스터의 이름과 로깅을 원하는 위치를 지정해야 함
실행 모드를 고를 수 있는데 장기적으로 실행되는 클러스터 모드와 단계 실행 모드가 존재하며
단계 실행 모드는 분석만 실행한 후 클러스터가 종료할 때 사용되는 모드
이후 EMBR의 릴리스를 선택해야 함
릴리스에는 여러 가지가 있도 모두 포함하고 있는 기술이 다름
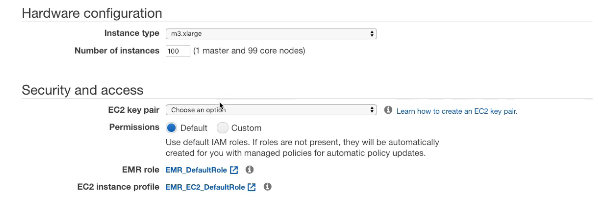
그리고 EMR 클러스터의 인스턴스 유형과 개수를 지정할 수 있어 100개까지 지정할 수 있음
또한 키 페어와 일부 권한 등을 제공하는 SSH 액세스를 설정하여 클러스터를 생성할 수 있음
'Cloud > AWS' 카테고리의 다른 글
| [SAA] AWS Workspaces (0) | 2022.05.06 |
|---|---|
| [SAA] OpsWorks (0) | 2022.05.06 |
| [SAA] Step Function 및 SWF (0) | 2022.05.06 |
| [SAA] CloudFormation 소개 (0) | 2022.05.06 |
| [SAA] CICD 소개 (0) | 2022.05.06 |
Amazon EMR
- Elastic MapReduce로 MapReduce는 빅데이터 용어이므로 EMR은 빅데이터에 사용되는 Hadoop 클러스터를 생성
그러므로 EMR은 Hadoop 프레임워크를 제공하며 클러스터를 생성하고 데이터를 업로드할 수 있음
+) S3에서도 업로드됨 - 빅데이터는 많은 양의 데이터인 페타바이트, 테라바이트 정도를 분석 및 처리하는데 사용
- EMR에서 생성하는 클러스터는 수백 개의 EC2 인스턴스로 구성될 수 있음
- EMR은 인스턴스들이 동시에 작동할 수 있게 조정하고 구성할 수 있음
- EMR을 통해 Hadoop 클러스터 구성을 한 후,
우리는 단지 Spart, HBase, Presto, Flink 등의 엔진을 사용해 데이터를 분석하고 처리만 함 - EMR은 모든 것을 프로비저닝하고 모든 것을 구성
- EMR과 작동하는 오토 스케일링이 존재하며 스팟 인스턴스로 통합되어 있으므로
빅데이터 분석 비용을 절감하고 싶다면 스팟 인스턴스를 사용 - 클러스터 상태를 모니터링할 수 있으며 처리 진행 상황 또한 볼 수 있으며 S3에서 처리 결과를 볼 수 있음
- 데이터 처리, 머신 러닝, 웹 인덱싱, 빅데이터 등에 사용
<EMR 실습>
- EMR 클러스터 생성
EMR은 Hadoop 프레임워크를 제공하며 클러스터를 생성하고 데이터를 업로드할 수 있으며 S3에서도 업로드할 수 있음
이후 입력한 모든 정보를 생성하고 클러스터 상태를 모니터링할 수 있으며 처리 진행 상황을 볼 수 있음
또한 S3에서도 처리 결과를 볼 수 있음
클러스터를 생성하려면 클러스터의 이름과 로깅을 원하는 위치를 지정해야 함
실행 모드를 고를 수 있는데 장기적으로 실행되는 클러스터 모드와 단계 실행 모드가 존재하며
단계 실행 모드는 분석만 실행한 후 클러스터가 종료할 때 사용되는 모드
이후 EMBR의 릴리스를 선택해야 함
릴리스에는 여러 가지가 있도 모두 포함하고 있는 기술이 다름
그리고 EMR 클러스터의 인스턴스 유형과 개수를 지정할 수 있어 100개까지 지정할 수 있음
또한 키 페어와 일부 권한 등을 제공하는 SSH 액세스를 설정하여 클러스터를 생성할 수 있음
'Cloud > AWS' 카테고리의 다른 글
| [SAA] AWS Workspaces (0) | 2022.05.06 |
|---|---|
| [SAA] OpsWorks (0) | 2022.05.06 |
| [SAA] Step Function 및 SWF (0) | 2022.05.06 |
| [SAA] CloudFormation 소개 (0) | 2022.05.06 |
| [SAA] CICD 소개 (0) | 2022.05.06 |