
타이타닉 생존자 분석의 배경과 목적
- 배경과 목적
- 데이터 예측 모델 및 분석 경연 대회 사이트인 캐글에서 진행되었던 타이타닉 문제를 직접 풀어보기
- 문제 정의하기 - 데이터 불러오기 - 데이터 분석 - 데이터 전처리 및 특성 추출 - 모델 설계 및 학습 - 마무리
- 1. 어떤 부류의 승객들이 생존할 가능성이 높았는지에 대해 데이터 분석 (성별, 연령)
2. 머신 러닝 모델을 만든 후 승선한 사람들의 생존 유무 예측
- 구글 코랩 실행
- Colab (Colaboratory)를 사용하면 별도의 설치나 다운로드 없이 브라우저에서 파이썬을 작성하고 실행할 수 있음
- 새노트를 눌러서 진행
데이터 분석과 시각화
- 데이터 분석 : 시작해볼까요?
1. 수동으로 파일을 불러오기 위해 코드를 작성한 후 실행하여 파일(train.csv, test.csv)을 불러옴
2. 필요한 라이브러리 다운받기
3. 다운 받은 csv 파일들을 train과 test라는 이름을 가지고 다시 실행
4. head 함수를 사용해 상위 5개에 있는 데이터를 불러오기
5. shape 함수를 사용해 데이터의 열과 행의 갯수를 알기 (891, 12)의 경우 891명의 승객 데이터와 12개의 승객 특성
6. 결측치 (데이터에 누락된 정보가 있는지) 값이 있는지 확인하기 위해 isnull 함수를 사용 (false일 경우 결측치가 없음)
확인하기 쉽게 하기 위해서는 뒤에 sum 함수를 붙여 한 눈에 알아볼 수 있게 함 (0일 경우 결측치가 없음) - 데이터 필드 설명
Survived - 생존유무, target 값. (0 = 사망, 1 = 생존)
Pclass - 티켓 클래스. (1 = 1st, 2 = 2nd, 3 = 3rd)
Sex - 성별
Age - 나이(세)
Sibsp - sibiling + spouse : 함께 탑승한 형제자매, 배우자 수 총합
Parch - parent + children : 함께 탑승한 부모, 자녀 수 총합
Ticket - 티켓 넘버
Fare - 탑승 요금
Cabin - 객실 넘버
Embarked - 탑승 항구 : 제주항, 부산항 - tain.csv
예측 모델을 만들기 위해 사용하는 학습셋
각 탑승객의 신상 정보와 ground truth (생존유무)가 주어지며, 생존유무를 예측하는 모델을 만듦 - test.csv
학습셋으로 만든 모델을 가지고 예측할 탑승객 정보가 담긴 테스트셋






 0123456
0123456
- 데이터 시각화 : 어느 특성의 승객이 더 많이 살아남았는가
1. 시각화를 위한 라이브러리 다운받기
2. 함수 정의를 통해 막대그래프로 시각화
3. 성별에 따른 막대그래프
4. 승객의 경제적 지위에 따른 막대그래프
5. 같이 탄 형제 자매 수, 또는 배우자의 수에 따른 막대그래프
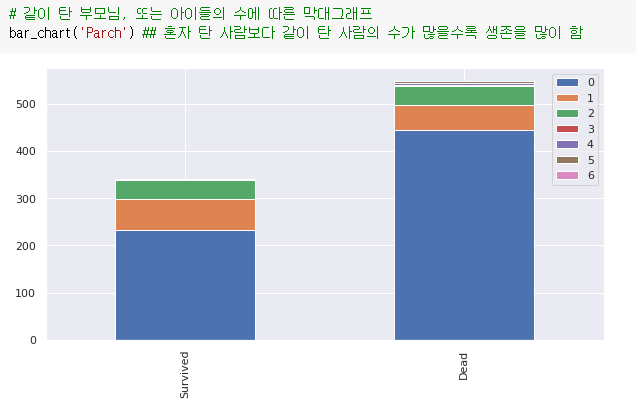
6. 같이 탄 부모님, 또는 아이들의 수에 따른 막대그래프
7. 탑승 항구에 따른 막대그래프





 0123456
0123456
데이터 전처리 및 특성추출
- Pandas & NumPy
- 데이터 전처리
예측할 모델에게 학습시킬 특성들을 골라서 학습하기에 알맞게 전처리해야 함 - 데이터셋
기본적으로 행렬(Column, Row)구조를 가지고 있음
예) Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked - Name Feature 전처리
예) Braund, Mr. Owen Harris
Miss, Mr 등의 Title로 승객의 성별이나 나이대, 결혼 유무를 알 수 있음
이름에서 Mr, Miss 등의 Title만 꺼내기 위해서는 공백 ' '으로 시작하고 끝이 마침표 .로 끝나는 정규표현식을 사용
사용되는 정규표현식 : ' ([A-Za-z]+)/.'
1. 전처리 하기 전에 train과 test 데이터를 한꺼번에 처리하기 위해 합친 후 Title이라는 Column을 추가하도록 함
2. 범주형 변수로 되어 있는 요인 별로 교차분석을 해서 행, 열 요인 별로 빈도를 세서 도수분포표 교차표를 만들어줌
3. 흔하지 않는 Title은 기타로 대체하고, 중복되는 표현은 통일한 후 Title과 Survived의 생존율의 평균을 표로 나타냄
4. 추출한 Title 데이터를 학습하기에 알맞게 String 데이터로 변형
+) 정규표현식 (Regular expressions)
특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어로
복잡한 문자열의 검색과 치환을 위해 사용되며 파이썬 뿐만 아니라 문자열을 처리하는 모든 곳에서 사용됨


 012
012
- Sex Feature 전처리
성별을 나타냄
별다른 전처리 작업이 필요 없으며 단지 String 데이터로 변형해주는 작업만 필요
1. Sex 데이터를 학습하기에 알맞게 String 데이터로 변형
 0
0
- Embarked Feature 전처리
배를 탑승한 선착장을 나타냄
1. Embarked 특징에는 결측치가 존재히므로 value_counts 함수로 결측치 확인
2. 결측치가 있으면 돌아가지 않으므로 fillas 함수를 이용해 다른 값으로 바꿔주거나 결측치 Row를 삭제시켜주어야 함
3. 학습하기에 알맞게 String 데이터로 변형
 0
0
- Age Feature 전처리
나이를 나타냄
연속적인 숫자 데이터를 처리하기 위해 Binning 기법을 이용하며 결측치의 경우 평균 Age를 넣어줌
Binning이란 연속성이 있는 데이터를 구간으로 나누어 범주화하는 방법
예) 16살의 간격으로 나누어, 해당 구간을 String 형식의 명칭을 사용하여 분리
1. fillas 함수를 이용해 결측치의 값을 Age의 평균으로 채워줌
2. 결측값이 없는지 다시 확인
3. 학습하기에 알맞게 String 데이터로 변형
4. cut 함수를 사용해 Age를 5개의 구간으로 나눔
5. print 함수를 사용해 나눈 Age의 구간과 생존율을 표로 나타냄
5. head 함수를 통해 AgeBand라는 새로운 Column이 추가되었음을 확인
6. loc 함수를 통해 행과 열을 조회해 구간으로 추가된 Age를 변형한 후 Age를 재조정하여 문자열을 String 데이터로 변형

 01
01
- Fare Feature 전처리
타이타닉 호를 타기 위해 지불한 비용을 나타냄
1. 비용이 좌석의 등급인 Pclass와 긴밀한 연관성을 가진다고 생각하여 Pclass를 가진 사람들의 평균값을 결측치로 넣어줌
2. cut 함수를 사용해 Fare를 5개의 구간으로 나눔
3. print 함수를 사용해 나눈 Fare의 구간과 생존율을 표로 나타냄
4. loc 함수를 통해 행과 열을 조회해 구간으로 추가된 Fare를 변형
5. 문자열을 int 데이터로 변형

 01
01
- Sib & Parch Feature (Family Feature) 전처리
타이타닉 호에 탑승한 형제자매 또는 배우자의 수 / 타이타닉 호에 탑승한 부모 또는 아이들의 수를 나타냄
둘 다 수가 많을수록 생존 확률이 높았으므로 함께 합쳐서 Family Feature 생성
1. 데이터셋에 Family라는 Column을 생성한 후 Sib과 Parch을 더한 값을 가진다고 정의한 후 int 데이터로 변형
 0
0
- 나머지 전처리
사용할 Feature에 대해서는 전처리가 다 끝났으므로 학습시킬 때 제외시킬 Feature들을 드롭시켜줌
1. 제외시켜줄 Column명을 넣어줌
2. train과 test에서 지정해준 Column 인덱스들을 모두 드롭해줌
3. train에서 탑승객의 아이디, 구간을 나누면서 사용했던 AgeBand, FareBand도 드롭해줌
4. 전처리가 끝난 데이터 확인
 0
0
- One-hot-encoding
범주형 변수에 대해 원핫인코딩을 한 후에 데이터와 레이블을 분리시키는 작업을 함
원핫인코딩이란 범주형 범주를 0 또는 1 값을 가진 하나 이상의 새로운 특성으로 바꾸는 것
0과 1로 표현된 변수는 선형 이진 분류 공식에 적용할 수 있어서 개수에 상관없이 범주마다 하나의 특성으로 표현
Pandas에서는 get_dummies 함수를 사용해 데이터를 매우 쉽게 인코딩 할 수 있으며
get_dummies 함수는 객체 타입(문자열 같은)이나 범주형을 가진 열을 자동으로 변환해줌
예) Age Feature에서 Young과 같은 문자열은 학습시킬 수 없으므로 각각 컬럼으로 만들어 준 후
Age 값이 Young이라면 Young 컬럼에만 1을 놔두고 나머지는 0으로 나두도록 하여 데이터를 이진화 시킴

 0
0
모델 설계 및 학습
- 지도 학습
입력과 출력 샘플 데이터가 있고 이러한 훈련셋으로부터 머신러닝 모델을 만들고 새로운 데이터에 대해 정확한 출력을 예측
이번 실습은 지도 학습 - 비지도 학습
알고 있는 출력값 정보 없이 학습 알고리즘을 가르쳐야하는 모든 종류의 머신 러닝으로 입력 데이터만으로 지식을 추출함 - 분류
지도 학습의 개념 중 하나로 미리 정의된 클래스 레이블 중 하나를 예측하는 것
예1) 탑승자의 생사 -> 2개의 클래스로 분류하므로 이진분류
예2) 상권 확장 정체 감소 -> 3개 이상의 클래스로 분류하므로 다중분류 - 회귀
지도 학습의 개념 중 하나로 연속적인 숫자나 수학 용어로 실수를 예측하는 것
예1) 집의 정보가 주어졌을 때 집값 예측
예2) 교육 수준, 나이, 주거지를 바탕으로 연간소득 예측 - Logistic Regression (로지스틱 회귀)
분류용 선형 모델로 입력의 선형 함수를 결정 결계라고 하며 새로 들어온 데이터를 예측
예) 데이터셋에서 첫 번째 특성을 x축에 놓고, 두 번째 특성을 y축에 놓았을 때, 대각선 직선으로 결정 결계가 표현되며
위쪽은 클래스1, 아래쪽은 클래스0으로 나누게 되며 새로운 데이터가 위쪽으로 들어오게 되면 1, 아래로 들어오면 0으로 분류

- Suport Vector Marchine (서포터 벡터 머신)
선형 서포트 벡터 머신은 로지스틱 회귀와 같은 분류형 선형 모델이며 훈련데이터의 일부만 결정경계를 만드는데 영향을 줌
결정 경계 근처에 있는 데이터만 결정 경계를 만드는데 영향을 주므로 이러한 데이터 포인터를 서포트 벡터라고 함
분류를 위한 선형 머신은 직선으로만 데이터 포인터를 나눌 수 있어서 중간과 같이 직선이 아니라 원을 그리는 데이터셋은 부적합
그러므로 하나의 특성을 추가하여 3차원 평면으로 나누어 두 클래스를 분류할 수 있게 됨
이렇게 확장된 3차원 공간을 다시 2차원으로 줄여서 투영을 하게 되면 타원에 가까운 모양을 보이는 것을 알 수 있으므로
비선형 특성을 가지며 특성을 많이 추가하게 되면 연산 비용이 커지며 비효율적인 것을 막기 위한 분류 기법인 커널기법을 사용


- k-NN (k-최근접 이웃 분류)
가장 간단한 머신러닝 알고리즘으로 훈련 데이터셋을 전달하기만 하는 것이 모델을 만드는 전부로
훈련 데이터셋에서 가장 가까운 데이터 포인트 최근접 이웃을 찾게 됨
예) test 데이터셋인 별이 가장 가까운 거리에 있는 train 데이터를 찾게 됨
이를 기반으로 한 KNeighborsClassifier는 이웃을 몇 개 찾을 것인가에 따라서 다른 분류를 보임
이웃의 수를 늘릴수록 경계가 부드러워지며 복잡도가 낮아지고, 이웃의 수를 적게할수록 경계가 부드럽지 않고 복잡도가 높아짐
이웃의 수가 적어 복잡도가 높다면, 새로운 데이터가 왔을 때 일반화된 예측을 보일 수 없게 되므로 적당한 이웃을 정해야 함


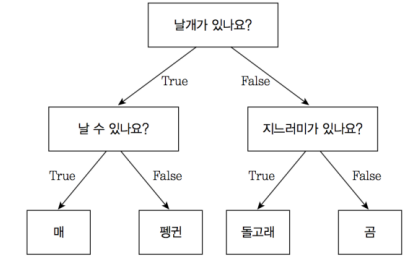
- Decision Tree (결정 트리)
분류와 회귀 문제에 널리 사용되며 결정에 다다르기 위해 예/아니오 질문을 이어나가면서 학습
예) 세 개의 특성을 사용해 네 개의 클래스를 구분하는 모델을 만든 것
트레이닝 데이터에 대해 정확한 예측도를 갖는다는 장점이 있지만
트레이닝 데이터에 과하게 맞는(과대적합)되는 경향이 있어 새로 들어온 데이터에 대한 일반화의 성능이 좋지 않음

- Random Forest (결정 트리의 앙상블인 랜덤 포레스트)
결정 트리의 단점을 해결하기 위한 앙상블로 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만든 것을 뜻함
랜덤 포레스트는 조금씩 다른 여러 결정트리의 묶음으로
각 트리는 비교적 예측을 잘 할 수 있지만 데이터 일부에 과대적합하는 경향을 가지므로
서로 다른 방향으로 과대적합된 트리를 만든 후 결과를 평균내어 최종적으로 과대적합된 양이 줄어들게 됨

- Naive Bayes (나이브 베이즈 분류기)
각 특성을 개별로 취급해서 파라미터를 학습하고 각 특성에서 클래스별 통계를 단순하게 취합하기 때문에
앞선 선형 모델보다 훈련 속도가 빠르지만 일반화 성능이 떨어짐
나이브 베이즈 중 GaussianNB는 연속적인 어떤 데이터에도 적용할 수 있으며 클래스별로 각 특성의 표준편차와 평균 저장

- 라이브러리 불러오기
위의 모델들의 라이브러리는 sklearn을 통해서 불러올 수 있음
sklearn은 오픈 소스로 파이썬 머신러닝 라이브러리

- 파이프라인
여러 처리 단계를 하나의 scikit-learn 추정기 형태로 묶어주는 파이썬 클래스
파이프라인은 fit, predict, score 메소드를 제공하고 scikit-learn의 다른 모델들과 유사하게 작동

- 결과
결과를 얻기 위해 어떠한 모델을 사용할 것인지 넣어줌

- 마무리
submission이라는 변수를 만들어서 Passenger Id의 컬럼을 test에서 가져온 후,
Random Forest의 결과를 Survived라는 컬럼으로 추가를 해서 DataFrame에 넣도록 함
그 후 submission.to_csv를 사용해 csv 파일로 저장하여 코랩 파일을 열어보거나 다운로드할 수 있음


+) k-NN (k-최근접분류)의 예측 결과를 담은 csv 파일 실습



타이타닉 생존자 분석하기.pdf
0.81MB
test.csv
0.03MB
train.csv
0.06MB
타이타닉 생존자 분석.ipynb
0.17MB
solux_3th_semina.csv
0.00MB
1915279_김가경_SOLUX.csv
0.00MB
'Community > SOLUX' 카테고리의 다른 글
| [220520] 2022 1학기 프로젝트 - 프로젝트 기획 발표회 (0) | 2022.05.24 |
|---|---|
| [220513] 2022 1학기 프로젝트 - 4차 회의 (0) | 2022.05.23 |
| [220506] 2022 1학기 프로젝트 - 3차 회의 (0) | 2022.05.06 |
| [220408] 2022 1학기 프로젝트 - 2차 회의 (0) | 2022.04.11 |
| [220401] 2022 1학기 프로젝트 - 1차 회의 (0) | 2022.04.01 |