
사전 훈련된 Word2Vec 임베딩 소개
- 자연어 처리 작업을 할 때
케라스의 Embedding()를 사용하여 갖고 있는 훈련 데이터로부터 처음부터 임베딩 벡터를 훈련시키기도 하지만,
반대로 방대한 데이터로 사전에 훈련된 워드 임베딩을 가지고 와서 해당 벡터들의 값을 작업에 사용할 수도 있음 - 훈련 데이터의 양이 부족하다면, Word2Vec, GloVe, FastText 등으로 사전 학습시킨 임베딩 벡터들을 가지고 와서 사용 가능
케라스 임베딩 층
- 케라스는 훈련 데이터의 단어들에 대해 워드 임베딩을 수행하는 도구인 Embedding()을 제공하며
Embedding()은 인공 신경망 구조 관점에서 임베딩층을 구현함 - 임베딩 층은 룩업 테이블
임베딩 층의 입력으로 사용하기 위해서는 입력 시퀀스의 각 단어들은 모두 정수 인코딩이 되어있어야 하며
임베딩 층은 입력 정수에 대해 밀집 벡터로 맵핑하고 이 밀집 벡터인 임베딩 벡터는 훈련을 하며 값을 업데이트하게 됨
이 과정에서 정수를 밀집 벡터(임베딩 벡터)로 맵핑하기 위해서는
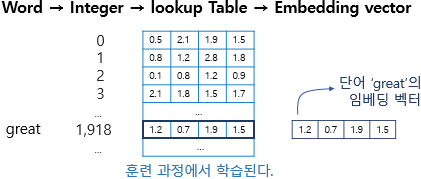
특정 단어와 맵핑되는 정수를 인덱스로 가지는 테이블로부터 임베딩 벡터 값을 가져오는 룩업 테이블을 하게 되고
이 테이블은 단어 집합의 크기만큼의 행을 가지므로 모든 단어는 임베딩 벡터를 가지게 됨
예) 임베딩 벡터의 차원이 4로 설정되어 있으며 단어 great는 정수 인코딩 과정에서 1918의 정수로 인코딩 되었고
그에 따라 단어 집합의 크기만큼의 행을 가지는 테이블에서 인덱스 1918번에 위치한 행을 단어 great의 임베딩 벡터로 사용
이 임베딩 벡터는 모델의 입력이 되고, 역전파 과정에서 단어 great의 임베딩 벡터값이 학습됨
- 임베딩 층
임베딩 층은 Embedding(vocab_size, output_dim, input_length)으로 세 개의 인자를 받음
vocab_size는 텍스트 데이터의 전체 단어 집합의 크기, output_dim은 워드 임베딩 후의 임베딩 벡터의 차원,
input_length는 입력 시퀀스의 길이를 나타냄
Embedding()은 2D 정수 텐서를 입력받은 후 워드 임베딩 작업을 수행한 후 3D 실수 텐서를 리턴하게 됨 - 임베딩 층 사용하기
1) 문장의 긍, 부정을 판단하는 감성 분류 모델을 만들기 위해 긍정인 문장은 레이블 1, 부정인 문장은 레이블 0으로 지정
2) 케라스의 토크나이저를 사용하여 단어 집합을 만들고 크기를 확인
3) 각 문장에 대해서 정수 인코딩을 수행
4) 가장 길이가 긴 문장의 길이를 구함
5) 최대 길이로 모든 샘플에 대해서 패딩을 진행
6) 출력층에 1개의 뉴런을 배치하고 활성화 함수로 시그모이드 함수, 손실 함수로 binary_crossentropy를 사용
7) 100 에포크 학습하여 현재 각 단어들의 임베딩 벡터들의 값이 출력층의 가중치와 함께 학습됨
사전 훈련된 워드 임베딩 사용하기
- 이미 훈련되어져 있는 워드 임베딩을 가져와서 임베딩 벡터로 사용하기도 함
- 훈련 데이터 이해하고 전처리하기
1) 앞서 케라스 임베딩 층에서 사용한 데이터를 사용 - 사전 훈련된 GloVe 사용하기
1) glove.6B.zip을 다운로드하고 압축을 푼 후 glove.6B.100d.txt 파일을 사용
2) glove.6B.txt에 있는 모든 임베딩 벡터를 불러온 후 딕셔너리를 사용해 로드한 임베딩 벡터의 개수를 확인
3) 임의의 단어 'respectable'의 임베딩 벡터 값과 크기를 출력
4) 벡터의 차원 수가 100이므로 풀고자 하는 문제의 단어 집합 크기의 행과 100개의 열을 가지는 행렬을 생성하고 0으로 채운 후
이 후 이 행렬에 사전 훈련된 임베딩 값을 넣어주도록 할 것임
5) 기존 데이터의 각 단어와 맵핑된 정수값을 확인하면 단어 'great'의 맵핑된 정수는 2
6) 사전 훈련된 GloVe에서 단어 'great'의 벡터값을 확인
7) 단어 집합의 모든 단어에 대해서 사전 훈련된 GloVe의 임베딩 벡터들을 임베딩 행렬에 맵핑한 후
'great'의 벡터값이 의도한 인덱스의 위치에 삽입되었는지 확인하기 위해 인덱스 2에서의 값을 확인하면
이전에 확인한 사전에 훈련된 GloVe의 'great'의 벡터값과 일치하는 것을 볼 수 있음
8) 임베딩 층에 embedding_matix를 초기값으로 설정하고 차원 수가 100이므로 output_dim을 100으로 설정함
그리고 사전 훈련된 워드 임베딩을 사용하므로 추가 훈련을 하지 않는다는 의미의 trainable의 인자값을 False로 선택해 훈련 - 사전 훈련된 Word2Vec 사용하기
1) 구글의 사전 훈련된 Word2Vec 모델을 gensim을 통해 로드하고 word2vec_model에 저장
2) 모델의 크기를 확인하면 3000000 x 300이므로 3백만 개의 단어와 각 단어의 차원은 300
3) 그렇기 때문에 3000000 x 300 x 4bytes를 하면 모델 파일의 크기는 3.3GB임을 알 수 있음
4) 벡터의 차원 수가 300이므로 풀고자 하는 문제의 단어 집합 크기의 행과 300개의 열을 가지는 행렬을 생성하고 0으로 채운 후
이 후 이 행렬에 사전 훈련된 임베딩 값을 넣어주도록 할 것임
5) 특정 단어의 임베딩 벡터가 없으면 None을 리턴하는 함수 get_vector()를 구현한 후
이를 사용해 None이 아니라면 임베딩 행렬에 해당 단어의 인덱스 위치의 행에 임베딩 벡터의 값을 저장하여 맵핑하도록 함
6) 사전 훈련된 Word2Vec에서 단어 'great'의 벡터값을 확인
7) 기존 데이터의 각 단어와 맵핑된 정수값을 확인하면 단어 'great'의 맵핑된 정수는 2
8) 'great의 벡터값이 의도한 인덱스의 위치에 삽입되었는지 확인하기 위해 인덱스 2에서의 값을 확인하면
이전에 확인한 사전에 훈련된 Word2Vec의 'great'의 벡터값과 일치하는 것을 볼 수 있음
9) 임베딩 층에 embedding_matix를 초기값으로 설정하고 차원 수가 300이므로 output_dim을 300으로 설정함
그리고 사전 훈련된 워드 임베딩을 사용하므로 추가 훈련을 하지 않는다는 의미의 trainable의 인자값을 False로 선택해 훈련
코드
GitHub - GaGa-Kim/ML_Study: 머신러닝 스터디 ⚙
머신러닝 스터디 ⚙. Contribute to GaGa-Kim/ML_Study development by creating an account on GitHub.
github.com
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 벡터 (0) | 2022.12.20 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 엘모 (0) | 2022.12.16 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 패스트텍스트 (0) | 2022.12.14 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 글로브 (0) | 2022.12.14 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 워드투벡터 (2) (0) | 2022.12.07 |
사전 훈련된 Word2Vec 임베딩 소개
- 자연어 처리 작업을 할 때
케라스의 Embedding()를 사용하여 갖고 있는 훈련 데이터로부터 처음부터 임베딩 벡터를 훈련시키기도 하지만,
반대로 방대한 데이터로 사전에 훈련된 워드 임베딩을 가지고 와서 해당 벡터들의 값을 작업에 사용할 수도 있음 - 훈련 데이터의 양이 부족하다면, Word2Vec, GloVe, FastText 등으로 사전 학습시킨 임베딩 벡터들을 가지고 와서 사용 가능
케라스 임베딩 층
- 케라스는 훈련 데이터의 단어들에 대해 워드 임베딩을 수행하는 도구인 Embedding()을 제공하며
Embedding()은 인공 신경망 구조 관점에서 임베딩층을 구현함 - 임베딩 층은 룩업 테이블
임베딩 층의 입력으로 사용하기 위해서는 입력 시퀀스의 각 단어들은 모두 정수 인코딩이 되어있어야 하며
임베딩 층은 입력 정수에 대해 밀집 벡터로 맵핑하고 이 밀집 벡터인 임베딩 벡터는 훈련을 하며 값을 업데이트하게 됨
이 과정에서 정수를 밀집 벡터(임베딩 벡터)로 맵핑하기 위해서는
특정 단어와 맵핑되는 정수를 인덱스로 가지는 테이블로부터 임베딩 벡터 값을 가져오는 룩업 테이블을 하게 되고
이 테이블은 단어 집합의 크기만큼의 행을 가지므로 모든 단어는 임베딩 벡터를 가지게 됨
예) 임베딩 벡터의 차원이 4로 설정되어 있으며 단어 great는 정수 인코딩 과정에서 1918의 정수로 인코딩 되었고
그에 따라 단어 집합의 크기만큼의 행을 가지는 테이블에서 인덱스 1918번에 위치한 행을 단어 great의 임베딩 벡터로 사용
이 임베딩 벡터는 모델의 입력이 되고, 역전파 과정에서 단어 great의 임베딩 벡터값이 학습됨
- 임베딩 층
임베딩 층은 Embedding(vocab_size, output_dim, input_length)으로 세 개의 인자를 받음
vocab_size는 텍스트 데이터의 전체 단어 집합의 크기, output_dim은 워드 임베딩 후의 임베딩 벡터의 차원,
input_length는 입력 시퀀스의 길이를 나타냄
Embedding()은 2D 정수 텐서를 입력받은 후 워드 임베딩 작업을 수행한 후 3D 실수 텐서를 리턴하게 됨 - 임베딩 층 사용하기
1) 문장의 긍, 부정을 판단하는 감성 분류 모델을 만들기 위해 긍정인 문장은 레이블 1, 부정인 문장은 레이블 0으로 지정
2) 케라스의 토크나이저를 사용하여 단어 집합을 만들고 크기를 확인
3) 각 문장에 대해서 정수 인코딩을 수행
4) 가장 길이가 긴 문장의 길이를 구함
5) 최대 길이로 모든 샘플에 대해서 패딩을 진행
6) 출력층에 1개의 뉴런을 배치하고 활성화 함수로 시그모이드 함수, 손실 함수로 binary_crossentropy를 사용
7) 100 에포크 학습하여 현재 각 단어들의 임베딩 벡터들의 값이 출력층의 가중치와 함께 학습됨
사전 훈련된 워드 임베딩 사용하기
- 이미 훈련되어져 있는 워드 임베딩을 가져와서 임베딩 벡터로 사용하기도 함
- 훈련 데이터 이해하고 전처리하기
1) 앞서 케라스 임베딩 층에서 사용한 데이터를 사용 - 사전 훈련된 GloVe 사용하기
1) glove.6B.zip을 다운로드하고 압축을 푼 후 glove.6B.100d.txt 파일을 사용
2) glove.6B.txt에 있는 모든 임베딩 벡터를 불러온 후 딕셔너리를 사용해 로드한 임베딩 벡터의 개수를 확인
3) 임의의 단어 'respectable'의 임베딩 벡터 값과 크기를 출력
4) 벡터의 차원 수가 100이므로 풀고자 하는 문제의 단어 집합 크기의 행과 100개의 열을 가지는 행렬을 생성하고 0으로 채운 후
이 후 이 행렬에 사전 훈련된 임베딩 값을 넣어주도록 할 것임
5) 기존 데이터의 각 단어와 맵핑된 정수값을 확인하면 단어 'great'의 맵핑된 정수는 2
6) 사전 훈련된 GloVe에서 단어 'great'의 벡터값을 확인
7) 단어 집합의 모든 단어에 대해서 사전 훈련된 GloVe의 임베딩 벡터들을 임베딩 행렬에 맵핑한 후
'great'의 벡터값이 의도한 인덱스의 위치에 삽입되었는지 확인하기 위해 인덱스 2에서의 값을 확인하면
이전에 확인한 사전에 훈련된 GloVe의 'great'의 벡터값과 일치하는 것을 볼 수 있음
8) 임베딩 층에 embedding_matix를 초기값으로 설정하고 차원 수가 100이므로 output_dim을 100으로 설정함
그리고 사전 훈련된 워드 임베딩을 사용하므로 추가 훈련을 하지 않는다는 의미의 trainable의 인자값을 False로 선택해 훈련 - 사전 훈련된 Word2Vec 사용하기
1) 구글의 사전 훈련된 Word2Vec 모델을 gensim을 통해 로드하고 word2vec_model에 저장
2) 모델의 크기를 확인하면 3000000 x 300이므로 3백만 개의 단어와 각 단어의 차원은 300
3) 그렇기 때문에 3000000 x 300 x 4bytes를 하면 모델 파일의 크기는 3.3GB임을 알 수 있음
4) 벡터의 차원 수가 300이므로 풀고자 하는 문제의 단어 집합 크기의 행과 300개의 열을 가지는 행렬을 생성하고 0으로 채운 후
이 후 이 행렬에 사전 훈련된 임베딩 값을 넣어주도록 할 것임
5) 특정 단어의 임베딩 벡터가 없으면 None을 리턴하는 함수 get_vector()를 구현한 후
이를 사용해 None이 아니라면 임베딩 행렬에 해당 단어의 인덱스 위치의 행에 임베딩 벡터의 값을 저장하여 맵핑하도록 함
6) 사전 훈련된 Word2Vec에서 단어 'great'의 벡터값을 확인
7) 기존 데이터의 각 단어와 맵핑된 정수값을 확인하면 단어 'great'의 맵핑된 정수는 2
8) 'great의 벡터값이 의도한 인덱스의 위치에 삽입되었는지 확인하기 위해 인덱스 2에서의 값을 확인하면
이전에 확인한 사전에 훈련된 Word2Vec의 'great'의 벡터값과 일치하는 것을 볼 수 있음
9) 임베딩 층에 embedding_matix를 초기값으로 설정하고 차원 수가 300이므로 output_dim을 300으로 설정함
그리고 사전 훈련된 워드 임베딩을 사용하므로 추가 훈련을 하지 않는다는 의미의 trainable의 인자값을 False로 선택해 훈련
코드
GitHub - GaGa-Kim/ML_Study: 머신러닝 스터디 ⚙
머신러닝 스터디 ⚙. Contribute to GaGa-Kim/ML_Study development by creating an account on GitHub.
github.com
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 벡터 (0) | 2022.12.20 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 엘모 (0) | 2022.12.16 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 패스트텍스트 (0) | 2022.12.14 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 글로브 (0) | 2022.12.14 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 워드투벡터 (2) (0) | 2022.12.07 |