
ELMo
- ELMo(Emdeddings form Language Model)는 새로운 워드 임베딩 방법론으로 '언어 모델로 하는 임베딩'을 뜻함
- ELMo의 가장 큰 특징은 사전 훈련된 언어 모델을 사용하며
같은 표기의 단어라도 문맥에 따라 다르게 워드 임베딩을 하여 자연어 처리의 성능을 올릴 수 있음 - 예) Bank Account(은행 계좌)와 River Bank(강둑)에서의 Bank는
Word2Vec나 GloVe 등으로 표현되면 같은 벡터를 사용하므로 제대로 반영하지 못함
biLM의 사전 훈련
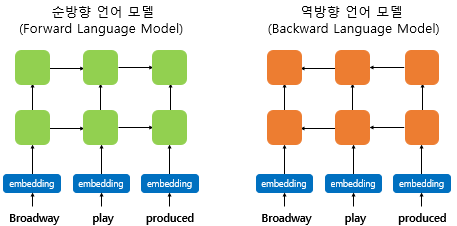
- ELMo는 순방향 RNN 뿐만 아니라, 반대 방향으로 문장을 스캔하는 역방향 RNN 또한 활용하므로
ELMo는 양쪽 방향의 언어 모델을 둘 다 학습하여 활용한다고 하여 biLM(Bidirectional Language Model)이라고 함 - ELMo에서 말하는 biLM은 기본적으로 은닉층이 최소 2개 이상인 다층 구조를 전제로 하며
각 시점의 입력이 되는 단어 벡터는 Word2Vec 등이 아닌, 합성곱 신경망을 이용한 문자 임베딩을 통해 얻게 됨
이러한 문자 임베딩은 서브단어의 정보를 참고하는 것처럼 문맥과 상관없는 단어들 사이의 연관성을 찾아낼 수 있음 - 추가적으로 양방향 RNN은 순방향 RNN의 은닉 상태와 역방향 RNN의 은닉 상태를 연결하여 다음층의 입력으로 사용하지만
biLM은 순방향 언어 모델과 역방향 언어 모델이라는 두 개의 언어 모델을 별개로 보고 학습하게 됨
biLM의 활용
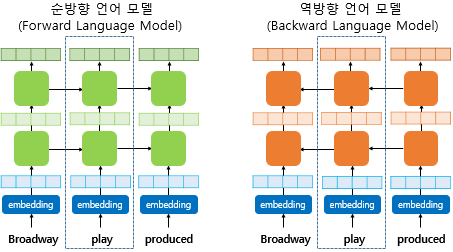
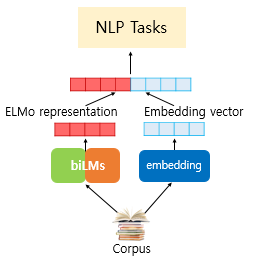
- biLM이 언어 모델링을 통해 학습된 후 ELMo가 사전 훈련된 biLM을 통해 입력 문장으로부터 단어를 임베딩하게 됨
- 'play'라는 단어를 임베딩하기 위해서 ELMo는 점선의 내부의 각 층의 결과값인 해당 시점의 biLM의 각 층의 출력값을 가져옴
그리고 순방향 언어 모델과 역방향 언어 모델의 각 층의 출력값을 연결하고 추가 작업을 진행하게 됨
- ELMo가 임베딩 벡터를 얻는 과정
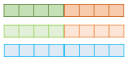
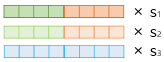
1) 각 층의 출력값을 연결한다.
2) 각 층의 출력값 별로 가중치를 준다.
3) 각 층의 출력값을 모두 더한다.
4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱한다.
이렇게 완성된 벡터를 ELMo 표현이라고 함
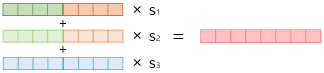
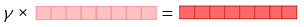
- ELMo 표현을 자연어 처리 작업인 텍스트 분류 작업에 사용하기
ELMo 표현을 기존의 임베딩 벡터와 함께 사용할 수 있으므로
우선 텍스트 분류 작업을 위해서 GloVe와 같은 기존의 방법론을 사용한 임베딩 벡터를 준비하고
여기에 준비된 ELMo 표현을 GloVe 임베딩 벡터와 연결해서 입력으로 사용할 수 있음
이때 biLM의 가중치는 고정시키고, 위에서 사용한 s1, s2, s3, y는 훈련 과정에서 학습되게 됨
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 임베딩 (0) | 2022.12.20 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 벡터 (0) | 2022.12.20 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 사전 훈련된 워드 임베딩 (0) | 2022.12.16 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 패스트텍스트 (0) | 2022.12.14 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 글로브 (0) | 2022.12.14 |
ELMo
- ELMo(Emdeddings form Language Model)는 새로운 워드 임베딩 방법론으로 '언어 모델로 하는 임베딩'을 뜻함
- ELMo의 가장 큰 특징은 사전 훈련된 언어 모델을 사용하며
같은 표기의 단어라도 문맥에 따라 다르게 워드 임베딩을 하여 자연어 처리의 성능을 올릴 수 있음 - 예) Bank Account(은행 계좌)와 River Bank(강둑)에서의 Bank는
Word2Vec나 GloVe 등으로 표현되면 같은 벡터를 사용하므로 제대로 반영하지 못함
biLM의 사전 훈련
- ELMo는 순방향 RNN 뿐만 아니라, 반대 방향으로 문장을 스캔하는 역방향 RNN 또한 활용하므로
ELMo는 양쪽 방향의 언어 모델을 둘 다 학습하여 활용한다고 하여 biLM(Bidirectional Language Model)이라고 함 - ELMo에서 말하는 biLM은 기본적으로 은닉층이 최소 2개 이상인 다층 구조를 전제로 하며
각 시점의 입력이 되는 단어 벡터는 Word2Vec 등이 아닌, 합성곱 신경망을 이용한 문자 임베딩을 통해 얻게 됨
이러한 문자 임베딩은 서브단어의 정보를 참고하는 것처럼 문맥과 상관없는 단어들 사이의 연관성을 찾아낼 수 있음 - 추가적으로 양방향 RNN은 순방향 RNN의 은닉 상태와 역방향 RNN의 은닉 상태를 연결하여 다음층의 입력으로 사용하지만
biLM은 순방향 언어 모델과 역방향 언어 모델이라는 두 개의 언어 모델을 별개로 보고 학습하게 됨
biLM의 활용
- biLM이 언어 모델링을 통해 학습된 후 ELMo가 사전 훈련된 biLM을 통해 입력 문장으로부터 단어를 임베딩하게 됨
- 'play'라는 단어를 임베딩하기 위해서 ELMo는 점선의 내부의 각 층의 결과값인 해당 시점의 biLM의 각 층의 출력값을 가져옴
그리고 순방향 언어 모델과 역방향 언어 모델의 각 층의 출력값을 연결하고 추가 작업을 진행하게 됨
- ELMo가 임베딩 벡터를 얻는 과정
1) 각 층의 출력값을 연결한다.
2) 각 층의 출력값 별로 가중치를 준다.
3) 각 층의 출력값을 모두 더한다.
4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱한다.
이렇게 완성된 벡터를 ELMo 표현이라고 함
- ELMo 표현을 자연어 처리 작업인 텍스트 분류 작업에 사용하기
ELMo 표현을 기존의 임베딩 벡터와 함께 사용할 수 있으므로
우선 텍스트 분류 작업을 위해서 GloVe와 같은 기존의 방법론을 사용한 임베딩 벡터를 준비하고
여기에 준비된 ELMo 표현을 GloVe 임베딩 벡터와 연결해서 입력으로 사용할 수 있음
이때 biLM의 가중치는 고정시키고, 위에서 사용한 s1, s2, s3, y는 훈련 과정에서 학습되게 됨
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 임베딩 (0) | 2022.12.20 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 벡터 (0) | 2022.12.20 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 사전 훈련된 워드 임베딩 (0) | 2022.12.16 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 패스트텍스트 (0) | 2022.12.14 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 글로브 (0) | 2022.12.14 |