
훈련 데이터에 대한 이해
- 텍스트 분류의 경우 지도 학습에 속하며 지도 학습의 훈련 데이터는 레이블이라는 이름의 미리 정답이 적혀있는 데이터로 구성됨
- 예) 스팸 메일 분류기의 훈련 데이터는 메일의 내용과 해당 메일이 정상 메일인지, 스팸 메일인지 적혀있는 레이블로 구성
- 이를 이용해 기계가 샘플 데이터를 학습한 후에 모델이 잘 설계되면
훈련 데이터에 존재하지 않았던 어떤 메일 텍스트가 주어지더라도 정확한 레이블을 예측할 수 있음

훈련 데이터와 테스트 데이터
- 갖고 있는 전체 데이터를 전부 훈련에 사용하는 것보다는 테스트용은 일부 남겨놓는 것이 바람직함
- 그 후 훈련이 끝나면 보류해두었던 테스트용 데이터를 가지고 정확도를 계산할 수 있음
- 예) 텍스트 데이터의 열을 X, 레이블 데이터를 y라고 할 때
훈련 데이터(X_train, y_train)와 테스트 데이터(X_test, y_test)로 분리한 후,
모델은 X_train과 y_train을 학습하고
X_test에 대해서 레이블을 예측하게 되고 모델이 예측한 레이블과 y_test를 비교해서 정확도를 계산함
단어에 대한 정수 부여
- 단어를 빈도수 순대로 정렬하고 순차적으로 정수를 부여하는 정수 인코딩이 필요함
- 그 후 케라스의 Embedding()은 단어 각각에 대해 정수로 변환된 입력에 대해서 임베딩 작업을 수행함
RNN으로 분류하기
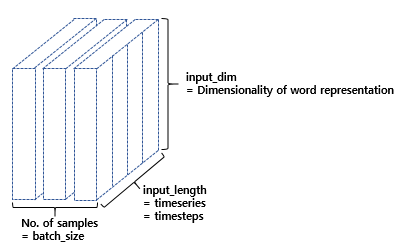
- RNN 코드의 인자로는 hidden_units, timesteps, input_dim이 존재함
hidden_units은 RNN의 출력의 크기이자 은닉 상태의 크기를 뜻하고
timesteps은 시점의 수이자 각 문서에서의 단어 수를 뜻하며
input_dim은 입력의 크기이자 임베딩 벡터의 차원을 뜻하게 됨
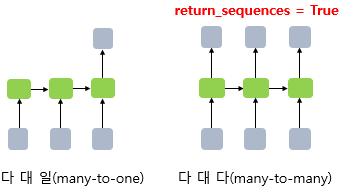
RNN의 다-대-일 문제
- 텍스트 분류는 모든 시점에 대해서 입력을 받지만 최종 시점의 RNN 셀만이 은닉 상태를 출력하고
이것이 출력층으로 가서 활성화 함수를 통해 정답을 고르므로 RNN의 다 대 일 문제에 속함 - 이 때 두 개의 선택지 중에서 정답을 고를 경우 이진 분류 문제,
세 개 이상의 선택지 중에서 정답을 고를 경우 다중 클래스 분류 문제라고 하며
이진 분류의 경우 출력층의 활성화 함수로 시그모이드 함수를 사용하고 손실 함수로는 binary_crossentropy를 사용함
반면 다중 클래스 분류 문제의 경우 출력층의 활성화 함수로 소프트맥스 함수를 사용하고
손실 함수로는 categorical_crossentropy를 사용하게 됨
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 10. RNN을 이용한 텍스트 분류 - LSTM으로 로이터 뉴스 분류하기 (0) | 2022.12.22 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 10. RNN을 이용한 텍스트 분류 - RNN으로 스팸 메일 분류하기 (0) | 2022.12.21 |
| [딥 러닝을 이용한 자연어 처리 입문] 10. RNN을 이용한 텍스트 분류 - 텍스트 분류 (0) | 2022.12.21 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 독투벡터 (0) | 2022.12.20 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 임베딩 (0) | 2022.12.20 |
훈련 데이터에 대한 이해
- 텍스트 분류의 경우 지도 학습에 속하며 지도 학습의 훈련 데이터는 레이블이라는 이름의 미리 정답이 적혀있는 데이터로 구성됨
- 예) 스팸 메일 분류기의 훈련 데이터는 메일의 내용과 해당 메일이 정상 메일인지, 스팸 메일인지 적혀있는 레이블로 구성
- 이를 이용해 기계가 샘플 데이터를 학습한 후에 모델이 잘 설계되면
훈련 데이터에 존재하지 않았던 어떤 메일 텍스트가 주어지더라도 정확한 레이블을 예측할 수 있음
훈련 데이터와 테스트 데이터
- 갖고 있는 전체 데이터를 전부 훈련에 사용하는 것보다는 테스트용은 일부 남겨놓는 것이 바람직함
- 그 후 훈련이 끝나면 보류해두었던 테스트용 데이터를 가지고 정확도를 계산할 수 있음
- 예) 텍스트 데이터의 열을 X, 레이블 데이터를 y라고 할 때
훈련 데이터(X_train, y_train)와 테스트 데이터(X_test, y_test)로 분리한 후,
모델은 X_train과 y_train을 학습하고
X_test에 대해서 레이블을 예측하게 되고 모델이 예측한 레이블과 y_test를 비교해서 정확도를 계산함
단어에 대한 정수 부여
- 단어를 빈도수 순대로 정렬하고 순차적으로 정수를 부여하는 정수 인코딩이 필요함
- 그 후 케라스의 Embedding()은 단어 각각에 대해 정수로 변환된 입력에 대해서 임베딩 작업을 수행함
RNN으로 분류하기
- RNN 코드의 인자로는 hidden_units, timesteps, input_dim이 존재함
hidden_units은 RNN의 출력의 크기이자 은닉 상태의 크기를 뜻하고
timesteps은 시점의 수이자 각 문서에서의 단어 수를 뜻하며
input_dim은 입력의 크기이자 임베딩 벡터의 차원을 뜻하게 됨
RNN의 다-대-일 문제
- 텍스트 분류는 모든 시점에 대해서 입력을 받지만 최종 시점의 RNN 셀만이 은닉 상태를 출력하고
이것이 출력층으로 가서 활성화 함수를 통해 정답을 고르므로 RNN의 다 대 일 문제에 속함 - 이 때 두 개의 선택지 중에서 정답을 고를 경우 이진 분류 문제,
세 개 이상의 선택지 중에서 정답을 고를 경우 다중 클래스 분류 문제라고 하며
이진 분류의 경우 출력층의 활성화 함수로 시그모이드 함수를 사용하고 손실 함수로는 binary_crossentropy를 사용함
반면 다중 클래스 분류 문제의 경우 출력층의 활성화 함수로 소프트맥스 함수를 사용하고
손실 함수로는 categorical_crossentropy를 사용하게 됨
'ML > 딥 러닝을 이용한 자연어 처리' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 10. RNN을 이용한 텍스트 분류 - LSTM으로 로이터 뉴스 분류하기 (0) | 2022.12.22 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 10. RNN을 이용한 텍스트 분류 - RNN으로 스팸 메일 분류하기 (0) | 2022.12.21 |
| [딥 러닝을 이용한 자연어 처리 입문] 10. RNN을 이용한 텍스트 분류 - 텍스트 분류 (0) | 2022.12.21 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 독투벡터 (0) | 2022.12.20 |
| [딥 러닝을 이용한 자연어 처리 입문] 09. 워드 임베딩 - 문서 임베딩 (0) | 2022.12.20 |