Target Tracking Scaling 목표 추적 조정 가장 단순하고 설정하기 쉬움 예) 평균 CPU 사용률을 추적하여 약 40%를 유지
Simple / Step Scaling 단순 / 단계 조정 CloudWatch 알람을 설정 예) CPU가 전체 ASG의 70& 이상을 사용했을 때 용량의 두 가지 유닛을 추가, 30% 미만이 되면 유닛 하나를 제거 단계로 설정할 경우 얼마나 많은 유닛을 동시에 추가하거나, 제거하기를 원하는지 정의가 필요
Scheduled Actions 계획된 행동 알려진 사용자의 패턴에 기반하여 조정이 예상됨 예) 매주 금요일 오후 5시에 큰 이벤트가 있으므로 ASG의 자동 최소 용량을 10으로 끌어올리기
Auto Scaling Groups – Predictive Scaling
예견된 조정 (예측에 기반하여 미리 계획도니 조정 작업 수행)
AWS의 자동 조정 서비스에 의해 예측을 지속적으로 할 수 있음
로드는 시간이 지나면서 계속해서 분석이 되기 때문에 예측은 계속 생성됨
Good metrics to scale on
CPUUtilization CPU 사용률 매번 인스턴스가 요청을 받으면 일종의 계산을 하고 일부의 CPU를 사용하게 되므로 전체 인스턴스의 평균 CPU 사용률을 보고 사용률이 증가한다면 조정하기에 좋은 메트릭이 될 것임 Average CPU utilization across your instances
RequestCountPerTarget 목표당 요청 개수 한 번에 요청 당 1000의 최적 요청이 작동한다는 것을 알고 있으면 조정을 위해 사용 EC2 인스턴스당 요청 수가 안정적인지 확인하기 위해 사용 예) 세 개의 EC2 인스턴스에 하나의 ASG를 갖고 있으며 로드밸런서가 현재 모든 인스턴스 요청을 분산하고 있을 때 각각의 인스턴스들이 평균적으로 3개의 미해결 요청을 갖고 있으므로, 이 때의 목표 메트릭당 요청 개수의 값은 3
Average Network In / Out 앱이 네트워크 바운드라면 이를 조정으로 사용 예) 굉장히 많은 업로드와 다운로드가 있으면 네트워크가 EC2 인스턴스에 병목현상을 만들게 되므로 출입 네트워크 평균을 조정
Any custom metric 사용자 지정 메트릭 앱을 특정하게 만들고 그것에 기반하여 조정 정책을 직접 셋팅
Auto Scaling Groups - Scaling Cooldowns
조정 활동 이후 인스턴스를 추가하거나 제거할 때마다 기본적으로 5분이나 300초 동안 쿨다운 기간이 시작됨
쿨다운 기간 동안에는 메트릭을 안정화하기 위해 ASG는 추가적인 인스턴스를 런칭하거나 종료하지 않음
조정 활동이 발생했을 때 쿨다운 기본값이 효과가 있다면 이를 무시하고, 그렇지 않다면 조정 활동이 진행되어 런칭, 종료 실행 EC2 인스턴스 구성에 시간을 쓰지 않는다면 즉시 효력을 발휘할 수 있으므로 따라서 즉시 사용가능한 AMI를 사용해 EC2 인스턴스가 요청을 빨리 요청하거나 제공할 수 있도록 구성 시간을 줄이는 것이 좋음 또한 이를 통해 쿨다운 기간을 줄일 수 있고 ASG를 보다 동적으로 확장 및 축소할 수 있음
ASG에 대한 세부 모니터링을 활성화해 1분마다 하위 수준 2개의 메트릭에 접근하여 메트릭이 빠르게 업데이트 되도록 해야 함
<ASG 스케일링 정책 실습>
ASG 오토 스케일링 정책의 세 가지 범주 오토 스케일링 그룹에서 자동 조정에 세 가지가 존재 1) 동적 스케일링 2) 예측 스케일링 3) 예약된 작업
예약된 작업 향후 스케일링 작업을 예약할 수 있으며 희망 용량, 최소 용량, 최대 용량을 설정 일주일에 한 번인지, 매시간마다 인지, 특정한 예약 주기를 정할 수 있으며 시작 시간과 끝 시간을 정할 수 있음 설정이 아주 단순하며 미리 예정되어 있고 사전에 알고 있는 이벤트에 대해서 작업을 예약할 수 있음 예) 다음주 토요일에 대규모 프로모션이 진행될 때 사용
예측 스케일링 머신 러닝을 기반으로 하며 예측을 토대로 스케일링을 수행 과거를 바탕으로 실제 정책과 실제 스케일링을 살펴볼 필요가 있으므로 지표를 확인하며 지표에는 CPU 사용률, 네트워크 입출력량, 애플리케이션 로드 밸런서 요청 수, 사용자 지정 지표가 존재하며 이를 토대로 설정할 수 있음 예) 인스턴스 당 50%의 CPI 사용률을 대상으로 설정 또한 실제 지난주 예약된 사용률을 기반으로 예측이 생성되며 이에 따라 ASG가 스케일링됨
동적 스케일링 세 가지 옵션이 존재하며 대상 추적 조정, 단계 조정, 단순 조정이 존재
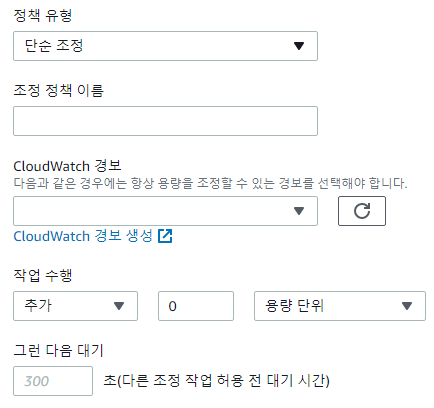
단순 조정의 경우 CloudWatch Alarm을 생성하여 경보가 발동될 때마다 용량이 스케일링되며 용량 유닛 두 개를 추가하고도록 설정하거나 그룹이 10%를 추가하도록 설정할 수 있으며 용량 유닛을 두 개로 합친 만큼의 유닛을 추가할 수도 있음
단계 조정의 경우 경보 값을 기준으로 여러 단계를 갖도록 다수의 경보를 설정할 수 있음 경보 값이 아주 높은 경우에는 10개의 용량 유닛을 추가하도록 설정할 수 있으며 너무 높지 않은 경우에는 하나만 추가하도록 할 수 있음
대상 추적 조정의 경우 CloudWatch 경보를 생성할 수 있으므로 이를 사용해 경보를 생성 정책 이름은 Target Tracking Policy이며 평균 CPU 사용률의 대상 값을 40으로 두고 추적하도록 함 만약 이를 초과할 경우 용량 유닛을 추가하도록 설정하여ASG의 CPU 사용률을 40%로 유지하도록 함
단순 조정단계 조정대상 추적 조정생성된 대상 추적 조정 정책
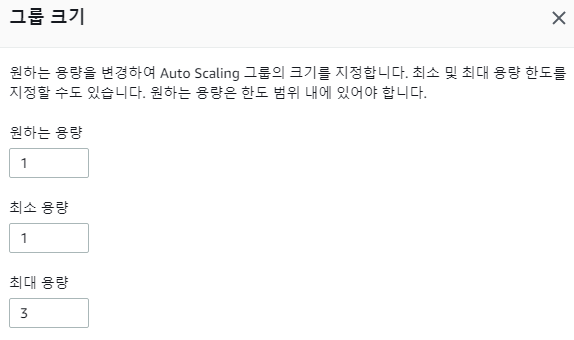
동적 스케일링 작동 확인 이 정책이 작동하는 것을 보려면 오토 스케일링 그룹의 용량 중 최대 용량을 1에서 3으로 변경해야 함 이를 통해 최대 용량이 최소 용량을 넘어 1에서 2나 3까지 증가하도록 설정
그리고 오토 스케일링 그룹의 모니터링에서 CPU 사용률을 보게 되면 사용률이 0으로 나오므로100%에 달하도록 stress를 설정 이를 위해 EC2 인스턴스로 이동한 다음 연결을 이용해서 EC2 인스턴스에 연결하고 구글에 install stress Amazon Linux 2를 입력하여 나오는 명령을 복해서 입력한 후 stress를 설치하고 실행 이후 다시 ASG를 살펴보면 CPU 사용률이 높게 상승한 것을 볼 수 있음 그 후 활동과 인스턴스 관리를 살펴보게 될 경우 경보가 발동하여 대상 추적 정책으로 인해 용량이 하나의 인스턴스에서 두 개의 인스턴스로 늘어났다는 것을 확인할 수 있음
대상 추적 정책에 대한 경보 확인 CloudWatch 서비스로 이동한 후 경보를 선택하여 대상 추정 정책에 대해 두 개의 경보가 생성된 것을 볼 수 있음 하나의 AlarmHigh로 스케일 아웃 시에 인스턴스를 추가하고 다른 하나의 AlarmLow로 스케일 인일 때 인스턴스를 제거 AlarmHigh는 CPU 사용률이 3분 이내에 세 개의 데이터 포인트에 대해 40%에 도달하는지 확인하고 경보 상태로 바꾸며 AlarmLow는 CPU 사용률이 15분 이내에 15개 데이터 포인터가 28%에 도달하는지 확인하고 작동 이로써 AlarmHigh의 지표가 CPU 사용률이 제한치를 초과함으로써 경보 상태로 발동된 상태임을 알 수 있으며 이로 인해 오토 스케일링 그룹에 대한 스케일링 활동이 수행되어 새로운 인스턴스가 사용되기 시작한 것
stress 명령을 중지한 후 인스턴스를 재부팅할 경우 CPU 사용률이 다시 0으로 돌아가고 15분 이내에 스케일링 작업이 시작되어 CPU 사용률이 다시 감소하여 28%라는 임계값을 지나 AlarmLow 경보가 작동하여ASG가 인스턴스를 제거하기 시작함