도메인 구입 도메인을 구입해야만 도메인을 등록할 수 있음 도메인을 검색한 후, 연락처 세부 정보를 확인한 후 구매 연락처 세부 정보에서 개인 정보 보호 옵션을 활성화하면 도메인에 대한 상세 연락처가 숨겨지게 됨 연락처 세부 정보를 확인하면 자동으로 Route 53을 이용해서 도메인을 관리하게 됨
도메인 등록 호스팅 존으로 가서 방금 구매한 도메인 이름에 대한 새로운 호스팅 존을 볼 수 있음 타입은 Public이고 Route53에 의해 직접 만들어지며, 레코드 개수는 2개이고 NS 레코드와 SOA 레코드가 존재 NS는 이름 서버를 뜻하며 도메인 이름에 대해 서버들은 권한 있는 답으로 테이블에 있는 어떤 레코드의 값이든 줄 수 있음
테이블에 있는 4개의 레코드 값
<첫 번째 레코드 생성 실습>
첫 번째 레코드 생성 호스팅 존으로 가서 레코드를 생성한 후 이름을 입력한 후 레코드의 종류를 A 레코드로 설정 A 레코드는 도메인 이름을 IPv4 주소로 라우팅하는 것을 뜻하며 값으로 11.22.33.44를 입력해 보여주기 위해 무작위로 입력 나중에는 실제 기관의 인스턴스로 라우팅할 것임 TTL은 300초로 해두며 라우팅 정책은 단순으로 설정
브라우저에서 생성된 레코드 확인 도메인의 호스팅 존을 보면 값이 무엇인지 요청할 것이고 호스팅 존은 값이 11.22.33.44라고 대답하게 됨 웹 브라우저에서 11.22.33.44를 열더라도 해당 IP 관련 서버가 없기 때문에 URL에 접근해도 동작하지 않음
클라우드 셸에서 생성된 레코드 확인 클라우드 셸에서 sudo yum install -y, bind-utils를 설치한 후 nslookup test.stephanetheteacher.com 명령을 동작하면 test.stephanetheteacher.com은 11.22.33.44로 보내지게 됨 또는 dig test.stephanetheteacher.com명령을 동작하면 응답 섹션이 보이고 test.stephanetheteacher.com 은 A 레코드이며 TTL은 269, 레코드의 값은 11.22.33.44라고 볼 수 있음
<EC2 설정 실습>
Route53을 진행하기 전 EC2와 애플리케이션 로드밸런서의 설정을 위해 EC2 인스턴스 생성 EC2 인스턴스를 세 개 유저 데이터를 작성하며 이전과 동일하게 프리티어로 생성한 후 세계 각국의 서로 다른 공인 IP 주소 사용 각 EC2 인스턴스의 공인 IP는 ap-southeast-1의 IP는 54.251.92.166, us-east-1의 IP는 54.172.8.44, eu-central-1의 IP는 3.70.14.253
애플리케이션 로드밸런서 생성 demo-alb-route-53을 생성한 후 서브넷을 3개로 설정하고 포트 80에서 트래픽을 허용하도록 새 보안 그룹을 생성 demo-tg-route53 이름으로 새 대상 그룹도 대상 타입을 인스턴스로 하여 생성하며 eu-central-1 인스턴스를 대상으로 추가 이후 만들어진 DNS 이름인 demo-alb-route-53-1648128207.eu-central-1.elb.amazonaws.com 을 복사해둠
인스턴스가 올바르게 설정되었는지 확인 세 개의 인스턴스의 공인 IP를 입력하여 Hello World를 띄워주며 동작하는지 확인 ALB가 준비되면 DNS 이름으로도 접속이 가능해짐
Route 53 – Records TTL (Time To Live)
레코드 TTL은 Time To Live를 뜻 함
클라이언트가 DNS Route 53과 웹 서버에 접근하고 있을 때 myapp.example.com에 대한 DNS 요청을 하여 DNS로부터 "A 레코드에 해당하고 IP는 12.34.56.78이며 300초의 TTL이 있음" 이라는 답변을 받게 됨 TTL은 클라이언트들에게 이 결과를 TTL의 지속 기간 동안 캐시하길 요구하므로 300초 동안 클라이언트는 결과를 캐시 이 때 만약 클라이언트가 다시 동일한 호스트 네임으로 DNS 요청을 하거나 접근한다면 답이 이미 캐시되었고 캐시 기간인 TTL 기간 동안 캐시 내에 있기 때문에 클라이언트는 DNS 시스템으로 쿼리를 보내지 않음 이를 사용하는 이유로는 레코드가 많이 바뀌는 것을 바라지 않기 때문에 DNS를 너무 자주 쿼리하지 않도록 하는 것 그리하여 클라이언트는 이미 가지고 있는 답을 사용해 웹 서버에 접근하여 HTTP 요청 및 응답을 함
높은 TTL – 예 : 24시간으로 TTL을 설정할 경우, 24시간 동안 캐시되어 있어 더 적은 클라이언트가 요청하므로 Route 53의 트래픽이 감소하여 아마도 오래된 레코드를 갖게 됨 만약 레코드를 변경하고 싶다면 24시간을 기다려야 하며 모든 클라이언트는 캐시에 새로운 레코드를 갖게 될때까지 기다려야 함
낮은 TTL – 예 : 60초로 TTL을 설정할 경우, DNS에 더 많은 트래픽을 행하므로 Route 53의 트래픽이 증가하고 Route 53에 도달하는 요청 수에 따라 가격이 매겨지므로 더 큰 비용 지불 필요 하지만 레코드가 더 빨리 업데이트되며 레코드 변경을 쉽게 빨리할 수 있음
만약 레코드 변경을 계획하고 있다면 24시간 동안 TTL을 줄인 다음 모든 클라이언트에 낮은 새 TTL이 있다는 것을 알게 되면 모든 사람에 대해 업데이트되는 레코드 값을 변경한 다음 TTL을 늘림
<TTL 실습>
TTL 작동 방식을 알아보기 위해 새 레코드를 생성 demo라는 이름으로 레코드를 생성하며 앞에서 생성한 EC2 인스턴스 중 하나인 eu-central-1를 사용하며 TTL은 2분으로 설정 이를 통해 특정 IP 주소인 3.70.14.253로 향하는 A 레코드로 demo.stephanetheteacher.com이 생성됨
웹 브라우저에서 레코드 작동 확인 웹 브라우저에서 IP 주소를 붙여넣으면 자동으로 eu-central-1 인스턴스로 연결해주므로 A 레코드가 제대로 작동하고 있음
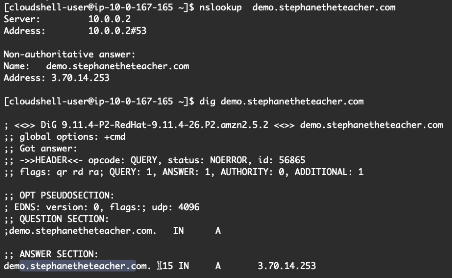
클라우드 셸에서 레코드 작동 및 TTL 확인 nslookup demo.stephanetheteacher.com를 실행하면 IP 주소가 나타나게 되며 dig 명령으로도 같은 결과가 나옴 또한 여기서 115라는 숫자를 볼 수 있는데 DNS 쿼리를 보냈기 때문에 120초 동안 레코드가 캐시된 것을 뜻하며 dig 명령을 다시 실행하게 되면 숫자가 98로 떨어지게 되며 98초 동안에는 같은 응답을 받게 될 거라는 것을 뜻하며 레코드가 다시 캐시되려면 98초가 더 걸린다는 것을 뜻하기도 함 캐시가 만료되고 나면 명령어 라인의 인터페이스(클라우드 셸)이나 웹 브라우저가 Route53에게 레코드 값을 다시 묻게 되고 그 후에 새 IP에 대한 결과를 받아 새 주소로 리다이렉팅되게 되어 새로고침을 할 경우 ap-southeast-1의 다른 IP가 뜨게 되는 것
CNAME vs Alias
CNAME과 Alias의 차이점
Load Balancer나 CloudFront와 같은 AWS 리소스는 호스트 이름을 노출하며, 이 때 호스트 이름을 도메인으로 매핑 필요 예) Load Balancer 1-1234.us-east-2.elb.amazonaws.com 를 myapp.mydomain.com 도메인으로 매핑
이 경우 두 가지 옵션이 존재
CNAME 레코드 사용 CNAME은 어떤 호스트 이름을 다른 모든 호스트 네임으로 가르킬 수 있도록 함 예) app.mydomain.com이 blabla.anything.com을 가르키고 있을 때, 루트가 아닌 도메인 네임을 가진 경우에만 작동 만약 something.mydomain.com을 갖고 있다면 mydomain.com에서는 작동하지 않으며 오직 루트가 아닌 경우에만 작동
Alias Alias는 Route 53만의 특징에 해당하며 호스트 네임이 특정한 AWS 리소스를 가르킬 수 있도록 함 예) app.mydomain.com이 blabla.amzonaws.com을 가르키고 있을 때, 루트 도메인과 루트가 아닌 도메인 모두에 작동 Alias로써 mydomain.com가 다른 Alias 리소스를 가리키게 할 수 있음 무료이며 네이티브 상태 확인 (Native Health Check) 기능을 내제하고 있음
Route 53 – Alias Records
Alias는 오직 AWS의 리소스에만 매핑됨
DNS 기능의 확장으로 존재하는 모든 DNS에 해당하며, ALB가 IP 주소 변경을 갖고 있는 경우 Alias 레코드는 자동으로 인식함
CNAME과 달리 Alias 레코드는 DNS 네임 장소의 최상위 노드인 Zone Apex에 사용될 수 있음
Alias 레코드는 example.com를 위해 사용할 수 있으며 Alias 레코드는 항상 A(IPv4) 또는 AAAA(IPv6) 타입에 해당
Alias 레코드를 갖고 있다면 TTL을 설정할 수 없으며 Route 53에 의해 자동으로 설정됨
예) Route 53이 있고 example.com가 A 타입의 Alias 레코드를 가지고 싶으며 Load Balaner의 DNS 네임을 value로 가질 때
Route 53 – Alias Records Targets
Elastic Load Balancers
CloudFront Distributions
API Gateway
Elastic Beanstalk environments
S3 Websites 버켓이 웹사이트로써 활성화된 경우에만 해당
VPC Interface Endpoints
Global Accelerator accelerator
동일한 호스팅 영역에 속한 Route 53 record
반면, EC2 DNS 네임에는 Alias를 설정할 수 없음 EC2 DNS 네임은 Alias 레코드의 목표 대상으로 가질 수 없음
<CNAEM vs Alias 실습>
CNAME 레코드 생성 도메인에 myapp이라고 이름을 붙인 뒤에 레코드 유형으로 CNAME을 선택하고 값으로는 ALB를 사용하여 생성 그럼 이 ALB의 URL을 통해 ALB에 접속하는 게 아니라 myapp.stepahntheteacher.com을 통해 접속하게 됨
CNAME 레코드 확인 myapp.stepahntheteacher.com 을 웹 브라우저에서 열게 되면 Hello World라는 문구가 AZ eu-central-1에서 뜨게 됨 이 도메인 이름은 실제로 ALB에 속해 있으면 ALB는 트래픽을 EC2 인스턴스로 보내고 있으므로 Hello World가 뜨게 되는 것
Alias 레코드 생성 ALB로 리다이렉팅을 하고 있기 때문에 별칭 레코드를 생성할 수 있음 myalias라는 이름을 붙인 뒤에 현재 ALB가 IPv4 트래픽만을 허용하고 있으므로 A 레코드로 타입을 정하먀 Route traffic to는 Alias to Application and Classic Load Balancer로 선택한 후 지역을 eu-central-1로 하며 ELB 로드밸런서를 클릭하여 생성 별칭 레코드이기 때문에 상태 확인은 자동으로 체크되어 있음
Alias 레코드 확인 별칭 레코드를 쿼리하는 것은 무료이며 myalias.stepahntheteacher.com을 클릭하면 DNS 쿼리를 몇 개 처리한 뒤 동일한 응답을 받을 수 있게 됨
도메인 apex를 고려해 stepahntheteacher.com만을 사용해 myalias.stepahntheteacher.com로 리다이렉트 하기 이를 위해서는 ALB의 도메인 이름인 demo-alb-route-53-1648128207.eu-central-1.elb.amazonaws.com로 향하는 CNAME 레코드를 생성해야 하는데 CNAME은 이 구역의 apex를 허용하지 않는다며 잘못된 요청이라고 나오게 됨 즉, 이 구역은 stepahntheteacher.com, 이 구역의 apex도 stepahntheteacher.com이니 CNAME을 apex에 설정할 수 없음 이 문제를 해결하기 위한 유일한 방법으로는 별칭 레코드를 생성하는 것이므로 레코드 타입을 A로 하여 eu-central-1 지역의 ALB로 향하는 위와 동일한 별칭 레코드를 생성 이렇게 하면 stepahntheteacher.com에 접속이 가능해지며 웹 브라우저에서 이를 검색하면 로드밸런서로부터 Hello World가 뜨게 되며 잘 작동 중인 것을 확인 가능
Route 53 – Health Checks
상태 확인은 주로 공인 리소스의 상태를 확인할 수 있는 방법이며, 프라이빗 리소스도 확인할 수 있음
예) 서로 다른 구역에 있는 두 개의 공인 로드 밸런서가 주어졌을 때, 두 개의 안에는 애플리케이션이 존재하며 리전 수준에서 높은 가용성을 위해 멀티 리전 셋업으로 실행하고 있음 이 때 DNS 레코드를 생성하기 위해 Route 53을 생성하며, URL에 사용자가 접근할 때 가장 가까운 로드 밸런서로 리다이렉트 하지만 이때 만약 하나의 로드 밸런서가 다운되어 있다면 그 곳으로는 보내면 안되므로 상태 확인을 생성하는 것 또한 이를 통해 자동화된 DNS 장애 조치를 얻을 수 있음
3개의 상태 확인이 존재
monitor an endpoint 퍼블릭 엔드포인트를 감시하는 상태 확인으로 애플리케이션, 서버, AWS 리소스가 대상이 될 수 있음
monitor other health checks (Calculated Health Checks) 또다른 상태 확인을 감시하는 상태 확인이 존재하며 계산된 상태 확인이라고 불림
monitor CloudWatch Alarms (helpful for private resources) CloudWatch Alarm을 감시하는 상태 확인이 존재하며, 이는 더 많은 통제를 하며 프라이빗 리소스에 있어서도 유용
상태 확인은 자신만의 메트릭이 있으며, CloudWatch 메트릭에서 확인할 수 있음
Health Checks – Monitor an Endpoint
상태 확인이 특정 엔드포인트와 함께 쓰일 때 어떻게 동작할까
예) eu-west-1과 ALB를 위한 상태 확인이 주어졌을 때, AWS의 Health Checker가 전세계로부터 약 15개가 왔다고 하면 이들이 루트를 어디로 설정하던지와 상관없이 요청을 퍼블릭 엔트포인트 /health로 보내줌 만약 이때 200 코드가 되돌아오거나 정의되면 리소스는 건강하다고 여겨짐
약 15개의 전세계적 Health Checker는 엔드 포인트의 상태를 확인할 것이며 그 후 건강하거나 건강하지 않은 상태의 최고점을 설정할 수 있고, 30초 또는 10초로 간격을 설정할 수 있음 10초의 경우 30초보다 더 많은 비용을 요구하며 빠른 상태 확인이라고 불림
상태 확인은 HTTP, HTTPS, TCP 같은 많은 프로토콜을 지원
만약 Health Checker의 18% 이상이 엔드 포인트가 건강하다고 말하면 Route 53은 건강하다고 인식함 그렇지 않은 경우에는 건강하지 않은 것을 여겨짐
상태 확인을 위해 사용할 위치를 선택할 수 있음
상태 확인은 로드밸런서로부터 2xx 또는 3xx 상태의 코드를 돌려받을 때만 패스할 수 있음
만약 텍스트 기반 응답인 경우, 응답에서 특정 텍스트를 찾아내기 위해 응답의 첫 5120 바이트를 확인할 수 있으며 이는 네트워크 관점에서 중요함
상태 확인을 작동시키면 Health Checker들은 반드시 애플리케이션의 로드밸런서나 엔드 포인트에 접근할 수 있어야 하므로 반드시 Route 53 상태 확인의 주소 범위로부터 들어오는 요청을 허용해야 함 위의 예시의 경우 하단에 있는 URL을 통해 확인할 수 있음
Route 53 – Calculated Health Checks
다수의 상태 확인에 따른 결과들을 단일의 상태 확인으로 결합
예) 3개의 EC2 인스턴스가 있는 Route 53에서는 세 개의 생태 확인을 생성할 수 있으며 이들은 child 상태 확인으로 각 EC2 인스턴스를 하나씩 감시할 수 있으며 그 후 Child 위에 Parent 상태 확인을 정의함 이 모든 상태 확인을 결합하기 위한 조건으로 OR, AND, NOT을 사용할 수 있음 256개의 Child 상태 확인을 감시할 수 있으며 Parent 상태 확인이 통과하기 위해 몇 개의 Child가 통과되어야 하는지 명시 가능
Health Checks – Private Hosted Zones
모든 Route 53 상태 확인은 Public Web에 살지만, 프라이빗 리소스의 경우 VPC 밖에 있으므로 프라이빗 엔드포인트에 접근할 수 없어 프라이빗 리소스의 상태를 감시하는 것은 어려움
이를 해결하기 위해 CloudWatch 메트릭을 생성하고 CloudWatch Alarm을 할당한 후 이를 상태 확인에 할당 그러므로 EC2 인스턴스의 상태를 오직 프라이빗 서브넷에서 CloudWatch 메트릭을 통해 감시하는 것이므로 만약 메트릭이 파괴되면 CloudWatch 경보 Alarm을 생성하며 이 상태가 되면 자동으로 상태 확인을 건강하지 않은 상태가 됨
<상태 점검 실습>
상태 확인 생성 전체 EC2 인스턴스용 상태 확인을 생성하기 위해 3가지 상태 확인을 생성 먼저 엔드 포인트가 될 us-east-1 인스턴스의 상태 확인을 생성하고 IP 주소나 도메인 이름을 지정 그리고 HTTP 포트이므로 80번으로 포트를 지정한 후, 웹 사이트 루트는 /와 동일하므로 /로 유지 실제 애플리케이션에서는 /health가 일반적이며 이는 엔드 포인트 자체의 상태에 관한 응답을 뜻함 고급 구성의 경우 상태 확인 요청 간격에 대해서 표준인 30초와 더 빠른 10초를 선택할 수 있으며 빠를 경우 비용이 더 발생 장애로 간주되기 전에 몇 번의 장애가 발생해야 하는지도 설정하며 첫 5120 바이트의 문자열을 비교할지 여부를 선택 그리고 시간 경과에 따른 지연 시간 확인을 위해 지연 시간 그래프를 볼지 선택하고 상태 확인의 리전을 지정 또한 상태 확인 장애 시 알림을 받을지의 여부를 선택할 수 있음 us-east-1의 첫 번째 상태 확인을 설정했으므로 ap-southeast-1과 eu-central-1의 상태 확인도 생성
상태 확인 장애 발생시키기 싱가폴에 있는 한 인스턴스의 보안 그룹에서 80번 포트를 차단하고 규칙을 삭제하여 상태 확인 장애를 발생시키고 보안 그룹으로 가서 인바운드 규칙에서 HTTP 관련 규칙을 삭제하면 ap-southeast-1의 상태 확인이 비정상으로 변경되게 됨 변경한 1개의 상태 확인은 비정상인 반면 보안 그룹을 변경하지 않은 나머지 2개는 정상 상태 상태 확인에서 확인해보면 마지막 확인 시간 등의 정보를 볼 수 있으며 오류가 발생한 것을 볼 수 있음 오류의 경우 연결 시간초과를 볼 수 있으며 요청이 방화벽으로 차단됐고 방화벽이 보안 그룹임을 알 수 있음
계산된 상태 확인 생성 calcultated라는 이름으로 Status of other health checks 상태 확인을 생성하여 다른 상태 확인의 상태를 확인하기 위해 모니터링하려는 상태 확인을 지정하여 3개의 상태 확인 중에서 1개가 정상일 때 보고를 받도록 지정하거나 2개 혹은 전체 정상인 경우를 AND를 사용하여 설정하거나 1개 이상의 상태 확인이 정상인 OR로 설정할 수 있음 또한 더 복잡한 규칙도 만들 수 있으며 이번은 모든 상태 확인이 정상일 때는 선택하여 상태 확인을 생성
CloudWatch 알람 상태의 모니터링 용 상태 확인 생성 State of CloudWatch alarm 상태 확인을 생성하며 알람이 발생할 지역을 지정해야 함 개인 리소스의 상태 확인을 Route53 상태 확인에 연결하여 개인 EC2 인스턴스의 상태를 모니터링할 수 있음
Route 53 –Traffic flow
트래픽 플로우 속성을 통해 복잡한 지리적 근접 레코드를 생성할 수 있으며 지리적 근접 레코드 이외에도 모든 것에 적용
크고 복잡한 구성에서 레코드 생성 및 유지 관리 프로세스 간소화
복잡한 리우팅 결정 트리의 관리를 돕는 UI인 Visual Editor가 주어지며 이를 통해 레코드를 Route 53의 DNS 관리 시스템에서 하나씩 적는 대신 이 모든 것을 한 번에 시각적으로 관리
이 구성은 트래픽 플로우 정책으로 저장되고 버전화될 수 있으며 다른 호스팅 영역에 적용될 수 있음