
핵심 키워드
- #특성 #훈련 #k-최근접 이웃 알고리즘 #모델 #정확도
- 가장 간단한 머신러닝 알고리즘 중 하나인 k-최근접 이웃을 사용하여 2개의 종류를 분류하는 머신러닝 모델을 훈련하자
생선 분류 문제
- 한빛 마켓에서 팔기 시작한 생선은 '도미', '곤들매기', '농어', '강꼬치고기', '로치', '빙어', '송어' 일 때
이 생선들을 프로그램으로 분류한다고 가정하면 어떻게 프로그램을 만들어야 할까? - 전통적인 프로그램
도미를 잘 아는 김팀장이 생선 길이가 30cm 이상이면 도미라는 규칙을 알려주어 이를 바탕으로 파이썬 프로그램을 작성
하지만 30cm보다 큰 생선이 무조건 도미라고 말할 수 없음
머신러닝은 누구도 알려주지 않는 기준을 찾아서 일을 하여 규칙을 찾으므로 이러한 문제를 머신러닝으로 해결할 수 있음
즉, 일반적인 프로그램 : 누군가가 사전에 규칙을 정해서 프로그램을 작성
머신러닝 프로그램 : 프로그램을 만들어서 규칙을 찾게끔 함 - 도미 vs 빙어
머신러닝은 여러 개의 도미 생선(데이터)을 보면 스스로 어떤 생선이 도미인지를 학습(훈련)하여 구분할 기준을 찾게 됨
이를 위해 도미 생선(데이터)를 많이 준비해둬야 함
머신러닝을 사용해 도미와 빙어를 구분하려고 하며 이를 2개의 클래스라고 하며
여러 클래스 중에서 하나를 구별해 내는 문제를 분류라고 하고, 도미와 빙어의 경우 2개의 클래스 중 하나를 고르므로 이진분류
도미와 빙어를 준비해서 무게와 길이를 재어보자 - 도미 데이터 준비하기
35마리의 도미를 준비하며 이러한 도미 데이터를 35개의 샘플이 존재한다고 말함
저울로 잰 도미의 길이와 무게를 파이썬 리스트로 만들며,
각 도미의 특징을 길이와 무게로 표현하는데 이러한 길이와 무게는 특성이라고 함
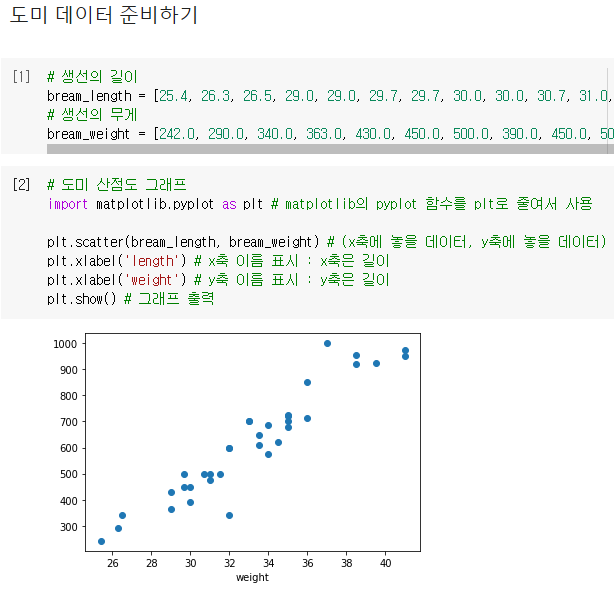
두 특성을 숫자로 보는 것보다 그래프로 표현하면 데이터를 잘 이해할 수 있으므로
길이를 X축으로 하고 무게를 Y축으로 하여 산점도(scatter plot)를 만들어 각 도미를 그래프에 점으로 표시
파이썬에서 과학계산용 그래프를 그리는 대표적인 패키지는 맷플롯립이므로 이 패키지를 임포트하고
산점도를 그리고 scatter() 함수를 사용해 도미 35마리를 2차원 그래프에 점으로 나타냄
- 빙어 데이터 준비하기
14마리의 빙어를 준비하여 도미와 빙어 데이터를 함께 2개의 산점도를 그래프로 그리기 위해 scatter() 함수를 연달아 사용
맷플롯립은 2개의 산점도를 색깔로 구분해주며 주황색 점이 빙어의 산점도이며 빙어는 도미에 비해 길이도 무게도 매우 작음

첫 번째 머신러닝 프로그램
- 도미와 빙어 합치기
생선을 분류하기 위해 k-최근접 이웃 알고리즘을 사용하려면 도미와 빙어 데이터를 하나의 데이터로 합쳐야 하므로
두 리스트를 더하여 하나의 리스트로 만들어 줌
그 후 사이킷런 머신러닝 패키지를 사용하기 위해서는 샘플 하나의 데이터가 하나의 리스트에 담기도록 변경해야 하므로
zip() 함수와 리스트 내포 구문을 사용해 각 특성의 리스트를 세로 방향으로 늘어뜨린 2차원 리스트로 만들어 줌
zip() 함수를 사용해 나열된 리스트 각각에서 하나의 원소씩을 꺼내 반환하고 리스트 내포 구문을 사용해 2차원 리스트로 만듦

- 정답 준비
머신러닝 알고리즘이 생선의 길이와 무게를 보고 도미와 빙어를 구분하는 규칙을 찾기를 원하므로
적어도 어떤 생선이 도미인지 빙어인지를 알려주어야 하며 이를 지도 학습이라고 함
이를 위해 도미와 빙어를 숫자 1과 0으로 표현하며
2개를 구분하는 경우 찾으려는 대상을 1로 놓고 그 외는 0으로 놓아야 하므로
도미를 찾는 대상으로 정의했기 때문에 도미를 1로 놓고 빙어를 0으로 놓음

- k-최근접 이웃
사이킷런 패키지에서 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트한 후
클래스 객체를 만들고 fish_data와 fish_target을 전달해 도미를 찾기 위한 기준을 학습시키는 훈련을 함
이를 위해 fit() 메소드를 사용해 fish_data와 fish_target을 순서대로 전달하고 주어진 데이터로 알고리즘을 훈련
객체 또는 모델인 kn이 얼마나 잘 훈련되었는지 평가하기 위해 score() 메소드를 사용해 모델을 평가
0에서 1사이의 값을 반환하며 1은 모든 데이터를 정확히 맞혔다는 것을 의미하며 이 값을 정확도라고 함

- 새로운 생선 예측
새로운 데이터가 있을 때 직관적으로 이 삼각형은 주변에 다른 도미 데이터가 많기 때문에 도미라고 판단할 것이며
k-최근접 이웃 알고리즘도 삼각형 주위에 도미 데이터가 많으므로 삼각형을 도미라고 판단할 것임
이를 확인하기 위해 predict() 메소드를 사용해 리스트의 리스트를 전달해 새로운 데이터의 정답을 예측
반환되는 값이 1이면 도미이며, 0이면 빙어이므로 새로 들어온 데이터인 삼각형은 도미


- 무조건 도미
k-최근접 이웃 알고리즘은 새로운 데이터에 대해 예측할 때 가장 가까운 직선거리에 어떤 데이터가 있는지 살피기만 하면 됨
k는 주위에서 바라볼 이웃의 개수를 뜻하고, 기본값은 5이므로 5개의 주변 샘플을 보고 판단함
이 기준은 n_neighbors 매개변수로 바꿀 수 있으며
이를 49로 바꾸어 가장 가까운 데이터 49개를 사용하는 k-최근접 이웃 모델에 fish_data를 적용하면
fish_data에 있는 모든 생선을 사용하여 예측하므로 fish_data의 데이터 49개 중에 도미가 35개로 다수를 차지하므로
어떤 데이터를 넣어도 무조건 도미로 예측하게 됨
이러한 kn49 모델은 도미만 올바르게 맞히기 때문에 정확도가 낮아지게 됨

+) 확인 문제
- n_neighbors의 기본값인 5부터 49까지 바꾸어 가며 점수가 1.0 아래로 내려가기 시작하는 이웃의 개수를 찾아보자
- k-최근접 이웃 알고리즘의 훈련은 데이터를 저장하는 것이 전부이기 때문에
객체를 매번 새로 만들거나 fit() 메소드를 통해 훈련할 필요가 없음

코드 링크
'ML > 혼자 공부하는 머신러닝 + 딥러닝' 카테고리의 다른 글
| [혼공머신] 03. 회귀 알고리즘과 모델 규제 - k-최근접 이웃 회귀 (0) | 2022.05.15 |
|---|---|
| [혼공머신] 02. 데이터 다루기 - 데이터 전처리 (0) | 2022.05.12 |
| [혼공머신] 02. 데이터 다루기 - 훈련 세트와 테스트 세트 (0) | 2022.05.11 |
| [혼공머신] 01. 나의 첫 머신러닝 - 코랩과 주피터 노트북 (0) | 2022.05.09 |
| [혼공머신] 01. 나의 첫 머신러닝 - 인공지능과 머신러닝, 딥러닝 (0) | 2022.05.09 |