
핵심 키워드
- #지도 학습 #비지도 학습 #훈련 세트 #테스트 세트
- 지도 학습과 비지도 학습의 차이를 배운 후
모델을 훈련 시키는 훈련 세트와 모델을 평가하기 위한 테스트 세트로 데이터를 나눠서 학습하자
지도 학습과 비지도 학습
- 머신러닝 알고리즘은 지도 학습과 비지도 학습으로 나눌 수 있음
- 지도 학습 알고리즘
훈련하기 위한 데이터와 정답이 필요하며 데이터와 정답을 입력과 타깃이라고 부르며, 이 둘을 합쳐 훈련 데이터라고 부름
정답(타깃)이 있으니 알고리즘이 정답을 맞히는 것을 학습
예) 도미인지 빙어인지 구분하는 k-최근접 이웃 알고리즘 - 비지도 학습 알고리즘
타깃 없이 입력 데이터만 사용하며 정답을 사용하지 않으므로 무언가를 맞힐 수 없음
예) 특성의 개수를 줄이거나, 비슷한 샘플을 모으는 작업을 수행하여 데이터를 잘 파악하거나 변형하는데 도움을 줌 - 강화 학습
모델이 행동을 수행한 다음, 주변의 환경에서 행동의 결과를 피드백받아 개선해 나가는 알고리즘
예) 알파고
훈련 세트와 테스트 세트
- 완벽한 보고서
앞의 경우, 도미와 빙어의 데이터와 타킷을 주고 학습한 다음, 같은 데이터로 테스트를 평가했으므로 모두 맞히는 것이 당연함
즉, fit() 메소드로 훈련을 할 때 사용한 데이터로 score() 메소드를 평가해서는 안된다는 뜻으로 이는 올바른 평가가 아님
그러므로 다른 데이터로 score() 메소드에서 테스트를 하는 것이 알고리즘의 성능을 평가하는 올바른 평가 방법이므로
훈련 데이터와 평가에 사용할 데이터가 각각 달라야 함
이렇게 하는 가장 간단한 방법은
1) 평가를 위해 또 다른 데이터를 준비
2) 이미 준비된 데이터 중에서 일부를 떼어 활용하는 것
이며 일반적으로 후자의 경우가 많으며, 평가에 사용하는 데이터를 테스트 세트, 훈련에 사용되는 데이터를 훈련 세트라고 함 - 훈련 세트와 테스트 세트
도미와 빙어의 데이터를 합쳐 하나의 파이썬 리스트로 준비한 후,
파이썬의 슬라이싱 연산자를 사용해 데이터의 처음 35개를 훈련 세트로, 나머지 14개를 테스트 세트로 사용
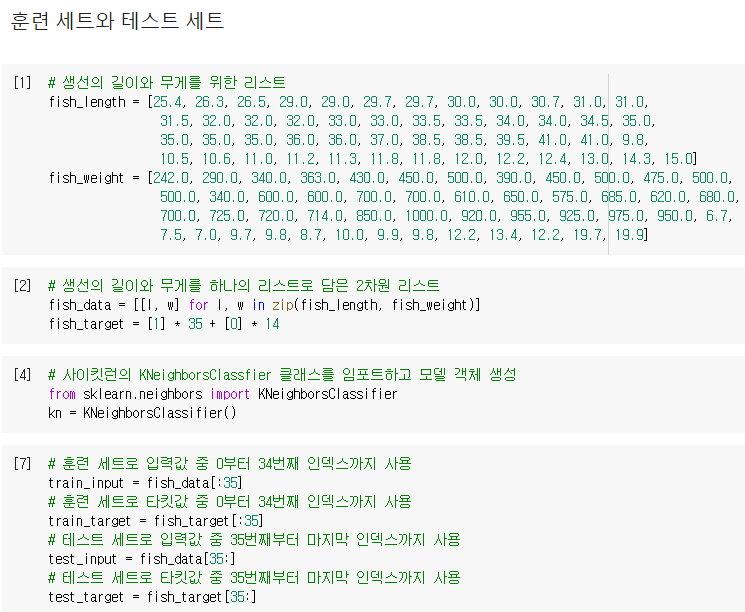
- 테스트 세트에서 평가하기
이 후 훈련 세트로 fit() 메소드를 호출해 훈련하고, 테스트 세트로 score() 메소드를 호출해 평가
하지만 이에 대한 정확도는 0.0으로 무언가 잘못 되었음

샘플링 편향
- 샘플링 편향
fish_data에는 처음부터 순서대로 35개의 도미와 14개의 빙어 샘플이 들어가 있으므로
따라서 마지막 14개를 테스트 세트로 만들면 빙어 데이터만 들어가게 됨
그리고 훈련 세트에 도미만 있기 때문에 테스트 세트가 무엇이든 무조건 도미라고 분류하며,
테스트 세트는 빙어만 있기 때문에 정답을 하나도 맞히지 못함
훈련하는 데이터와 테스트하는 데이터는 도미와 빙어가 골고루 섞여 있어야 함
훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 함
넘파이
- 넘파이 사용하기
넘파이는 파이썬의 대표적인 배열 라이브러리
파이썬의 리스트로 2차원 리스트를 표현할 수 있지만 고차원 리스트를 표현하려면 매우 번거로움
반면 넘파이는 고차원의 배열을 손쉽게 만드록 조작할 수 있는 간편한 도구를 많이 제공
1차원 배열을 선이고, 2차원 배열은 면, 3차원 배열은 공간을 나타냄
파이썬 리스트를 넘파이 배열로 바꾸기 위해서는 넘파이 라이브러리를 임포트한 후, 넘파이 array() 함수에 파이썬 리스트를 전달
출력 결과에서 49개의 행과 2개의 열을 쉽게 확인할 수 있음

- 데이터 섞기
생선 데이터를 넘파이 배열로 준비했으므로 이 배열에서 랜덤하게 샘플을 선택해 훈련 세트와 테스트 세트로 만들어야 함
한 가지 주의할 점은 정답을 제대로 알려 주기 위해서 input_arr와 target_arr에서 같은 위치는 함께 선택되어야 함
타킷이 샘플과 함께 이동하지 않으면 올바르게 훈련될 수 없으므로 이를 위해 배열을 섞지 않고, 배열의 인덱스를 섞는 방법 사용
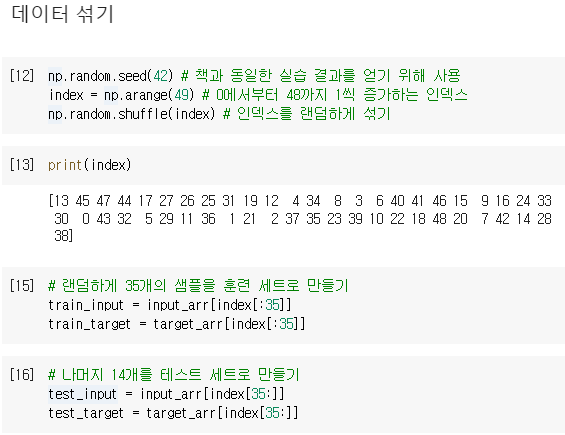
넘파이 arange() 함수를 사용하면 0에서부터 48까지 1씩 증가하는 인덱스를 만들 수 있고,
넘파이 random 패키지 아래 있는 shuffle() 함수를 사용해 주어진 배열을 무작위로 섞음
이 후 넘파이의 배열 인덱스 기능을 사용해
index 배열의 처음 35개를 input_arr와 target_arr에 전달하여 랜덤하게 35개의 샘플을 훈련 세트로 만들고
나머지 14개를 테스트 세트로 만듦
- 데이터 나누고 확인하기
훈련 세트와 테스트 세트에 도미와 빙어가 잘 섞여 있는지 확인하기 위해 산점도를 그려봄
2차원 배열은 행과 열 인덱스를 콤마로 나누어 지정하며,
슬라이싱 연산자로 처음부터 마지막 원소까지 모두 선택하는 경우 모두 생략 가능

두 번째 머신러닝 프로그램
- 두 번째 머신러닝 프로그램
앞서 만든 훈련 세트와 테스트 세트로 k-최근접 이웃 모델을 훈련시키기 위해
인덱스를 섞어서 만든 train_input과 train_target으로 모델을 훈련 시키고
test_input과 test_target으로 모델을 테스트하면
100%의 정확도로 테스트 세트에 있는 모든 생선을 맞히게 됨

'ML > 혼자 공부하는 머신러닝 + 딥러닝' 카테고리의 다른 글
| [혼공머신] 03. 회귀 알고리즘과 모델 규제 - k-최근접 이웃 회귀 (0) | 2022.05.15 |
|---|---|
| [혼공머신] 02. 데이터 다루기 - 데이터 전처리 (0) | 2022.05.12 |
| [혼공머신] 01. 나의 첫 머신러닝 - 마켓과 머신러닝 (0) | 2022.05.09 |
| [혼공머신] 01. 나의 첫 머신러닝 - 코랩과 주피터 노트북 (0) | 2022.05.09 |
| [혼공머신] 01. 나의 첫 머신러닝 - 인공지능과 머신러닝, 딥러닝 (0) | 2022.05.09 |