
핵심 키워드
- #k-평균 #클러스터 중심 #엘보우 방법
- k-평균 알고리즘의 작동 방식을 이해하고 과일 사진을 자동으로 모으는 비지도 학습 모델을 만들어보자
k-평균 알고리즘 소개
- 군집
비슷한 샘플끼리 그룹으로 모으는 작업을 군집이라고 함
군집은 대표적인 비지도 학습 작업 중 하나이며, 군집 알고리즘에서 만든 그룹을 클러스터라고 함
진짜 비지도 학습에서는 타깃값이 없기 때문에 이런 경우 평균을 구하기 위해서는 k-평균 군집 알고리즘을 이요
k-평균 군집 알고리즘은 평균값(중심)을 자동으로 찾아주며,
이 평균값이 클러스터의 중심에 위치하기 때문에 클러스터 중심 또는 센트로이드라고 부름 - k-평균
k-평균 알고리즘의 작동 방식
1. 무작위로 k개의 클러스터 중심을 정함
2. 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정함
3. 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경함
4. 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복함
k-평균 알고리즘의 작동 예시
1. 3개의 클러스텉 중심을 랜덤하게 지정함
2. 클러스터 중심에서 가장 가까운 샘플을 하나의 클러스터로 묶은 후
클러스터 중심을 다시 계산하여 이동 시킨 다음 가장 가까운 샘플을 다시 클러스터로 묶음
예시의 경우 사과2, 파인애플1이므로 사과 쪽으로 중심이 조금 더 이동하고, 바나나2, 사과1이므로 바나나 쪽으로 중심 이동
3. 클러스터에는 바나나와 파인애플, 사과가 3개씩 올바르게 묶여 있으며 다시 한 번 클러스터 중심을 계산
4. 위를 반복하여 만들어진 클러스터에 변동이 없으므로 k-평균 알고리즘을 종료
즉, k-평균 알고리즘은 처음에는 랜덤하게 클러스터 중심을 선택하고 점차 가장 가까운 샘플의 주임으로 이동하는 알고리즘

kMeans 클래스
- 모델 훈련
사이킷런의 k-평균 알고리즘은 sklearn.cluster 모듈 아래 KMeans 클래스에 구현되어 있으며
클러스터 개수를 지정하는 매개변수는 n_clusters가 있으며 여기에서는 클러스터 개수를 3으로 지정
이후 다른 메소드는 이전의 클래스들과 비슷하며, 다만 비지도 학습이므로 fit() 메소드에 타깃 데이터를 사용하지 않음
군집된 결과는 KMeans 클래스 객체의 labels_ 속성에 저장되며, labels_ 배열의 길이는 샘플 개수와 같음
이 배열은 각 샘플이 어떤 레이블에 해당되는지를 나타내며, n_clusters=3으로 지정했기 때문에 배열의 값은 0, 1, 2 중 하나
레이블 0, 1, 2로 모은 샘플의 개수를 확인하면
첫 번째 클러스터(레이블 0)가 91개의 샘플을 모았고, 두 번째 클러스터(레이블 1)가 98개의 샘플을 모았고
세 번째 클러스터(레이블 2)가 111개의 샘플을 모은 것을 알 수 있음

 01
01
- 첫 번째 클러스터
각 클러스터가 어떤 이미지를 나타냈는지 그림으로 출력하기 위해 draw_fruits() 유틸리티 함수를 생성
draw_fruits() 함수는 (샘플 개수, 너비, 높이)의 3차원 배열을 입력받아 가로로 10개씩 이미지를 출력함
이 함수를 사용해 레이블이 0인 과일 사진을 모두 그리기 위해서
km.labels_==0과 같이 쓰면 km.labels_ 배열에서 값이 0인 위치는 True, 그 외는 모두 False가 되므로
이렇게 넘파이는 불리언 배열을 사용해 원소를 선택하는 불리언 인덱싱을 사용할 수 있음
레이블 0으로 클러스터링된 91개의 이미지를 모두 출력하면 모두 사과가 올바르게 모인 것을 볼 수 있음

 01
01
- 두 번째, 세 번째 클러스터
레이블이 1인 클러스터는 바나나로만 이루어져 있음
하지만 레이블이 2인 클러스터는 파인애플에 사과 9개와 바나나 2개가 섞여 있음

 01
01
클러스터 중심
- 클러스터 중심 (평균)
KMeans 클래스가 최종적으로 찾은 클러스터 중심은 cluster_centers_ 속성에 저장되어 있음
이 배열은 fruits_2d 샘플의 클러스터 중심이기 때문에 이미지로 출력하려면 100 x 100 크기의 2차원 배열로 바꿔야 함
(10000인 1차원 배열 → 100 x 100인 2차원 배열)
또한 KMeans 클래스는 훈련 데이터 샘플에서 클러스터 중심까지 거리로 변환해 주는 transform() 메소드를 가짐
인덱스가 100인 샘플(101번째 샘플)에 transform() 메소드를 적용해보기 위해서는 2차원 배열을 제공해야 하므로
슬라이싱 연산자를 사용해서 (1, 10000) 크기의 2차원 배열을 전달하도록 함
하나의 샘플을 전달했기 때문에 반환된 샘플은 크기가 (1, 클러스터 개수)인 2차원 배열
그 결과로는 첫 번째 클러스터(레이블 0), 두 번째 클러스터(레이블 1), 세 번째 클러스터(레이블 2)까지의 거리가 출력되며
첫 번째 클러스터까지의 거리가 3393.8로 가장 작으므로 이 샘플은 레이블 0에 속할 것으로 보임
위의 결과를 확인하기 위해 KMeans 클래스에서 가장 가까운 클러스터 중심을 예측 클래스로 출력하는 predict() 메소드를 사용
위의 transform()의 결과에 따른 예측과 동일하게 레이블 0으로 예측하는 것을 볼 수 있음
그리고 이에 대한 클러스터 중심의 이미지를 그리면 레이블 0이므로 파인애플이 나오는 것을 볼 수 있음
+) k-평균 알고리즘은 반복적으로 클러스터 중심을 옮기면서 최적의 클러스터를 찾으며
알고리즘이 반복한 횟수는 KMeans 클래스의 n_iter_ 속성에 저장됨

최적의 k 찾기
- 최적의 k 찾기
k-평균 알고리즘의 단점 중 하나는 클러스터 개수를 사전에 지정해야 함
적절한 클러스터 개수를 찾기 위한 대표적인 방법은 엘보우 방법
k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있고, 이 거리의 제곱 합을 이너셔라고 부름
이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값으로 생각하며 작을수록 좋음
일반적으로 클러스터 개수가 늘어나면 클러스터 개개의 크기는 줄어들기 때문에 이너셔도 줄어듦
그러므로 엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법
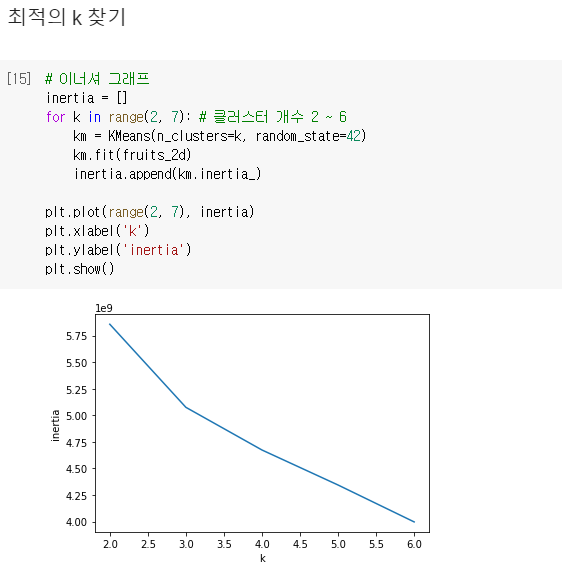
클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 존재하며
이 지점부터는 클러스터 개수를 늘려도 클러스터에 잘 밀접된 정도가 크게 개선되지 않음
KMeans 클래스는 자동으로 이너셔를 계산해서 inertia_ 속성으로 제공하므로
이를 이용해 클러스터 개수 k를 2~6까지 바꿔가며 KMeans 클래스를 fit() 메소드로 5번 훈련하고
inertia_ 속성에 저장된 이너셔 값을 inertia 리스트에 추가하여 저장된 값을 그래프로 출력함
이 그래프에서는 꺾이는 지점이 뚜렷하지는 않지만, k=3에서 그래프의 기울기가 조금 바뀐 것을 볼 수 있음
엘보우 지점보다 클러스터 개수가 많아지면 이너셔의 변화가 줄어들면서 군집 효과도 줄어들게 됨
하지만 이 그래프처럼 이런 지점이 명확하지 않을 수 있으므로
지도 학습과 같은 후속 작업을 하여 결과가 만족스러운지 확인하는 피드백 루프 대안이 필요함
'ML > 혼자 공부하는 머신러닝 + 딥러닝' 카테고리의 다른 글
| [혼공머신] 07. 딥러닝을 시작합니다 - 인공 신경망 (0) | 2022.07.05 |
|---|---|
| [혼공머신] 06. 비지도 학습 - 주성분 분석 (0) | 2022.06.30 |
| [혼공머신] 06. 비지도 학습 - 군집 알고리즘 (0) | 2022.06.28 |
| [혼공머신] 05. 트리 알고리즘 - 트리의 앙상블 (0) | 2022.06.01 |
| [혼공머신] 05. 트리 알고리즘 - 교차 검증과 그리드 서치 (0) | 2022.06.01 |