
핵심 키워드
- #LSTM #셀 상태 #GRU
- 순환 신경망에서 빼놓을 수 없는 핵심 기술인 LSTM과 GRU 셀을 사용한 모델을 만들어보자
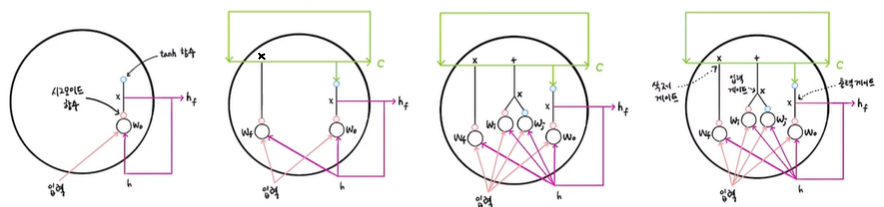
LSTM 구조
- LSTM 셀
LSTM은 Long Short-Term Memory의 약자로 단기 기억을 오래 기억하기 위해 고안되었음
LSTM에는 입력과 가중치를 곱하고 절편을 더해 활성화 함수를 통과시키는 구조를 여러 개 가지고 있으며
이런 계산 결과는 다음 타임스텝에 재사용됨
LSTM에서 은닉 상태를 만들기 위해서는 입력과 이전 타임스텝의 은닉 상태(h)를 가중치(w)에 곱한 후 활성화 함수를 통과시켜
다음 은닉 상태를 만드는데, 이때 기본 순환층과 달리 시그모이드 활성화 함수를 사용하며
또 tanh 활성화 함수를 통과한 어떤 값과 곱해져서 은닉 상태를 만들게 됨
은닉 상태를 계산할 때 사용하는 가중치는 Wo(Wx + Wh), 파란색 원은 tanh 함수, 주황색 원은 시그모이드 함수, X는 곱셈 표시
또한 LSTM에는 순환되는 상태가 은닉 상태와 셀 상태 2개이며,
은닉 상태와 달리 셀 상태는 다음 층으로 전달되지 않고 LSTM 셀에서 순환만 되는 값으로 c로 표시
먼저 입력과 은닉 상태(h)를 또 다른 가중치(Wf)에 곱한 후 시그모이드 함수를 통과시키고 이전 타임스텝의 셀 상태과 곱하여(x)
새로운 셀 상태가 만들어지며 이 셀 상태는 오른쪽에서 tanh 함수를 통과하여 새로운 은닉 상태(hf)를 만듦
즉, LSTM은 작은 셀을 여러 개 포함하고 있는 큰 셀 같으며,
은닉 상태에서 곱해지는 가중치인 Wo와 Wf는 다르므로 두 작은 셀은 각기 다른 기능을 위해 훈련됨
여기에 2개의 작은 셀이 더 추가되어 셀 상태를 만드는데 기여함
입력과 은닉 상태(h)를 각기 다른 가중치(Wi, Wj)에 곱한 다음, 하나는 시그모이드 함수를 통과하고 다른 하나는 tanh 함수 통과
그다음 두 결과를 곱한 후(x) 이전 셀 상태와 더하게 되어(+) 이 결과가 최종적인 다음 셀 상태((hf)가 됨
세 군데의 곱셈을 왼쪽부터 차례대로 삭제 게이트, 입력 게이트, 출력 게이트라고 부르며
삭제 게이트는 셀 상태에 있는 정보를 제거하는 역할을 하고 입력 게이트는 새로운 정보를 셀 상태로 추가하며
출력 게이트를 통해서 이 셀 상태가 다음 은닉 상태로 출력됨
LSTM 신경망 훈련하기
- LSTM 신경망
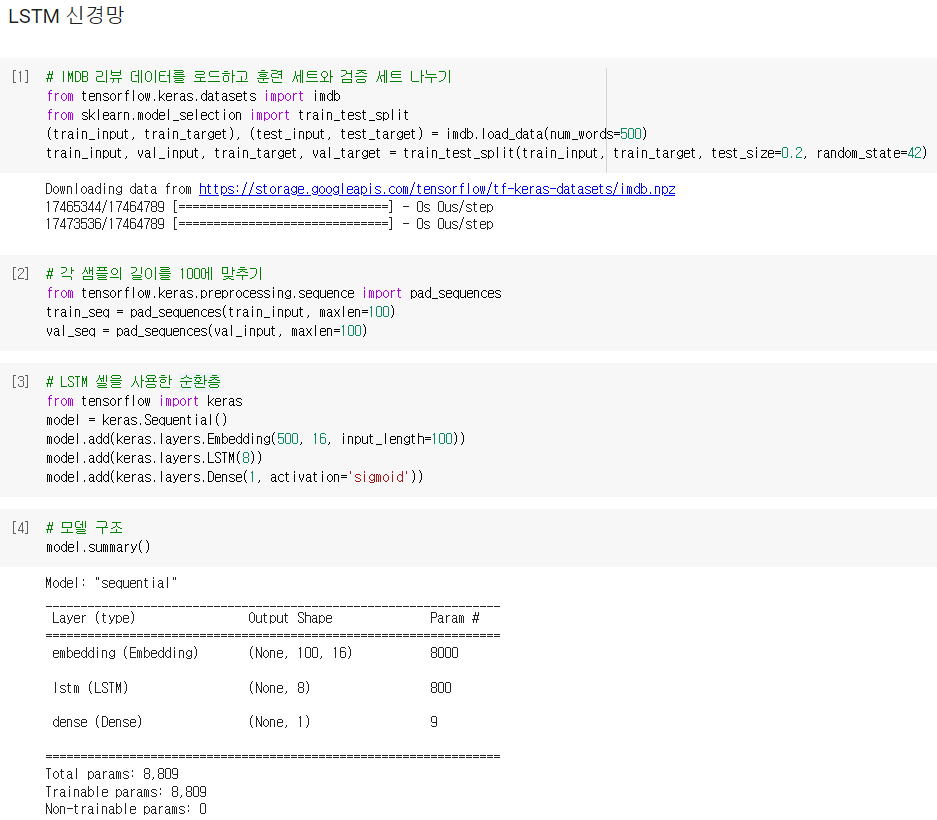
LSTM 셀을 사용한 순환층을 만들기 위해서는 SimpleRNN 클래스를 LSTM 클래스로 바꾸기만 하면 됨
모델 구조를 출력해보면 SimpleRNN 클래스의 모델 파라미터 개수는 16 x 8 + 8 x 8 + 8 = 200개이었지만
LSTM 셀에는 작은 셀이 4개 있으므로 정확히 4배가 늘어 모델 파라미터 개수는 (16 x 8 + 8 x 8 + 8 ) x 4 = 800개
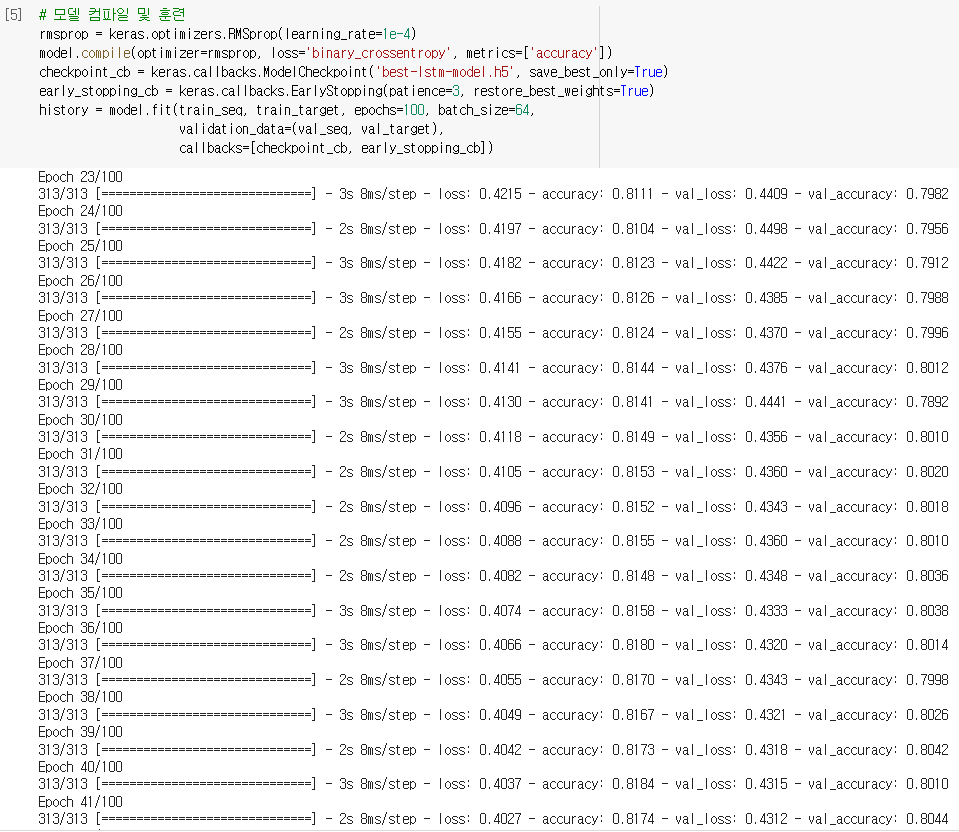
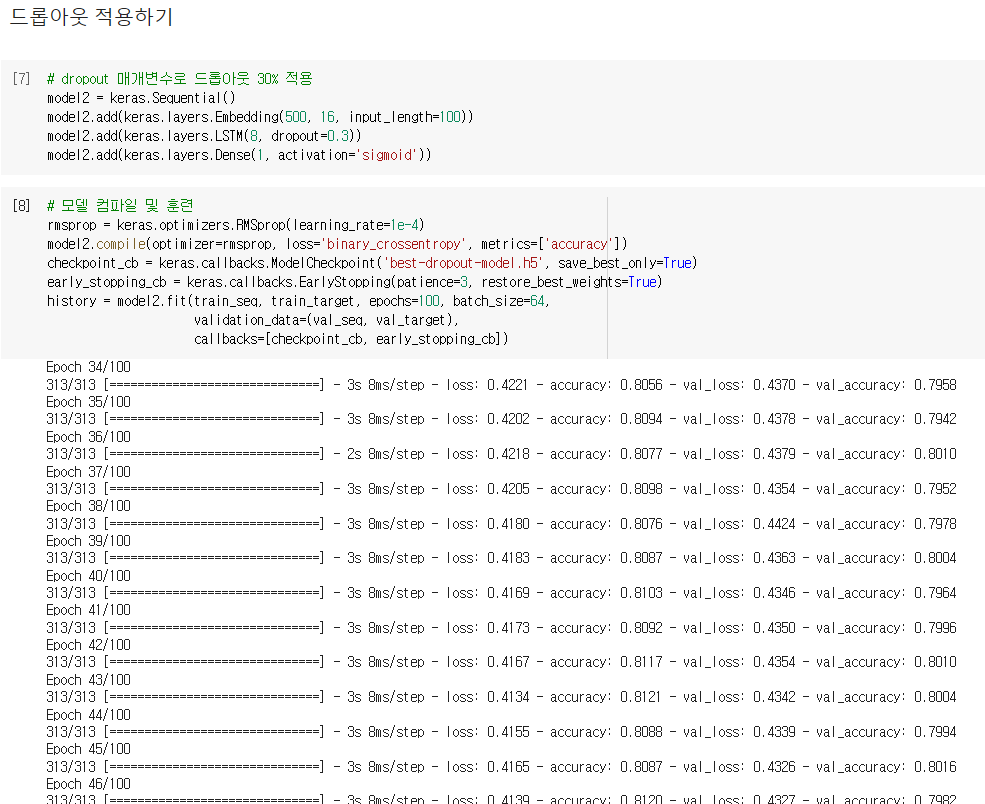
배치 크기는 64개, 에포크 횟수는 100, 체크포인트와 조기 종료를 위한 코드를 작성해 모델을 컴파일하고 훈련
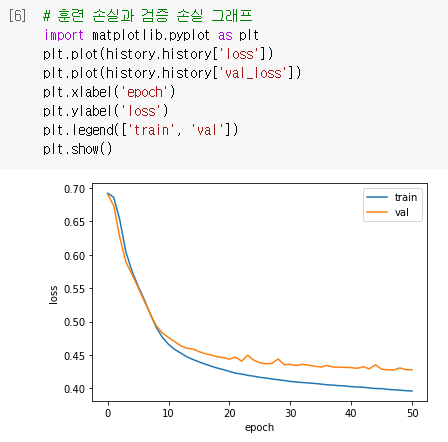
훈련 손실과 검증 손실 그래프를 그려보면 기본 순환층보다 LSTM이 과대적합을 억제하면서 훈련을 잘 수행한 것을 볼 수 있음
 012
012
순환층에 드롭아웃 적용하기
- 드롭아웃 적용하기
완전 연결 신경망과 합성곱 신경망에서는 Dropout 클래스를 사용해 드롭아웃을 적용했으나
순환층은 자체적으로 드롭아웃 기능을 dropout 매개변수와 recurrent_dropout 매개변수로 제공
dropout 매개변수는 셀의 입력과 드롭아웃을 적용하고 recurrent_dropout은 순환되는 은닉 상태에 드롭아웃을 적용
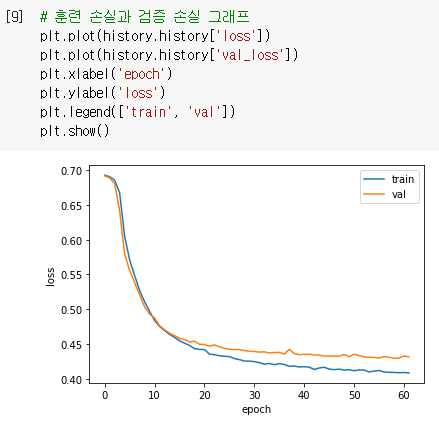
LSTM 클래스에 dropout 매개변수를 0.3으로 지정하여 30%의 입력을 드롭아웃하고 모델을 훈련하면 검증 손실이 향상됨
훈련 손실과 검증 손실 그래프를 그려보면 훈련 손실과 검증 손실 간의 차이가 좁혀진 것을 확인할 수 있음
 01
01
2개의 층을 연결하기
- 2개의 층을 연결하기
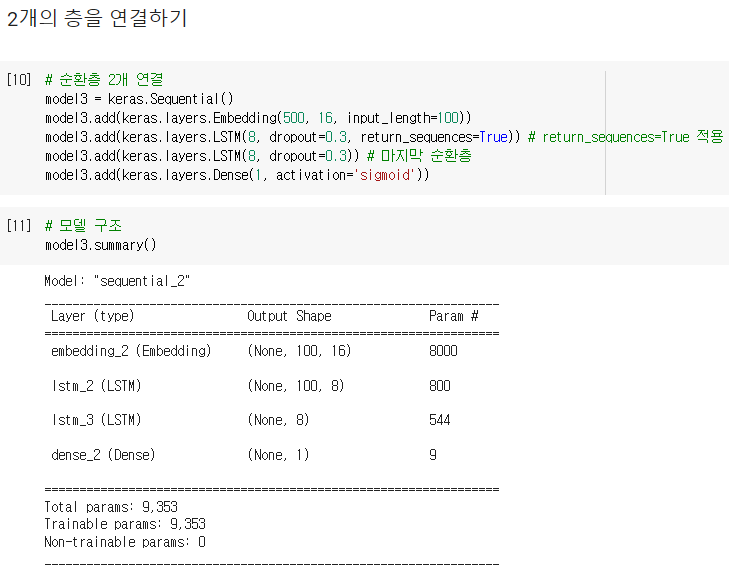
순환층의 은닉 상태는 샘플의 마지막 타임스텝에 대한 은닉 상태만 다음 층으로 전달하게 되지만
순환층을 쌓게 되면 모든 순환층에 순차 데이터가 필요하므로 앞쪽의 순환층이 모든 타임스텝에 대한 은닉 상태를 출력해야만 함
이를 위해 케라스의 순환층에서 모든 타임스텝의 은닉 상태를 출력하려면
마지막을 제외한 다른 모든 순환층에 return_sequences 매개변수를 True로 지정하면 됨
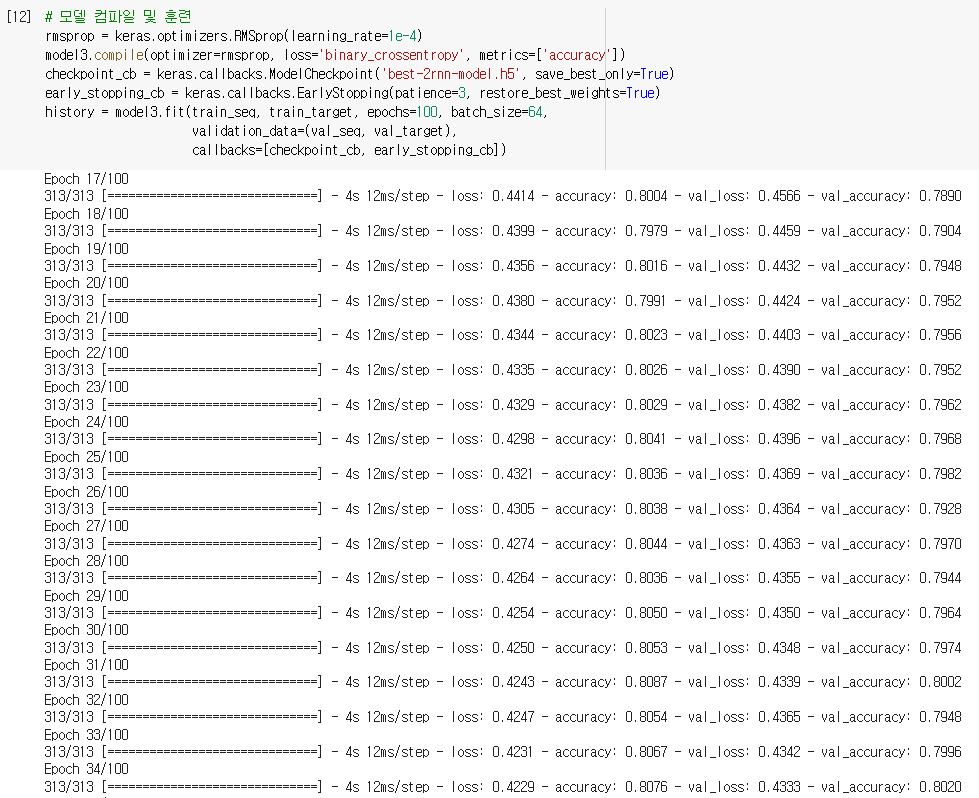
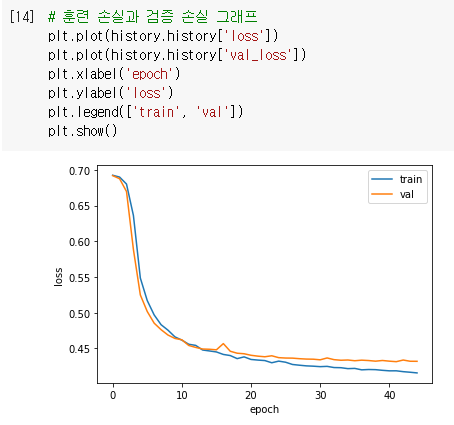
일반적으로 순환층을 쌓으면 성능이 높아지게 되며
손실 그래프를 그려서 과대적합이 잘 제어되었는지 확인하면 과대적합을 제어하면서 손실을 최대한 낮춘 것을 볼 수 있음
 012
012
GRU 구조
- GRU 셀
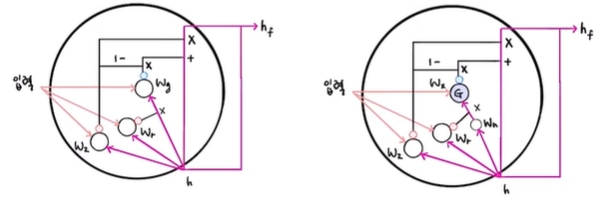
LSTM을 간소화한 버전이며, 이 셀은 LSTM처럼 셀 상태를 계산하지 않고 은닉 상태 하나만 포함하고 있음
GRU 셀에는 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀이 3개 들어있으며
2개는 시그모이드 활성화 함수를 사용하고 하나는 tanh 활성화 함수를 사용함
여기에서도 은닉 상태와 입력에 곱해지는 가중치(Wg = Wx + Wh)를 합쳐서 나타냄
맨 왼쪽에서 Wz를 사용하는 셀의 출력이 은닉 상태(h)에 바로 곱해져(x) 삭제 게이트 역할을 수행
이와 똑같은 출력을 1에서 뺀 다음(1-) Wg를 사용하는 셀의 출력에 곱하면(x) 이는 입력되는 정보를 제어하는 역할 수행
가운데 Wr을 사용하는 셀에서 출력된 값은 Wg 셀이 사용할 은닉 상태의 정보를 제어함
텐서플로에 기본적으로 구현된 GRU 셀의 계산은 위와 조금 다름
위에서는 Wg에 입력과 은닉 상태에 곱해지는 가중치(Wx, Wh)가 각각 합쳐져 들어가 있고
가운데 셀의 출력(Wr로 인한 출력)과 은닉 상태(h)가 곱해진 후(x) G 셀에 입력되었으나,
이번에는 은닉 상태(h)가 먼저 가중치(Wh)와 곱해진 다음 가운데 셀의 출력(Wr로 인한 출력)과 곱해지게 되므로
이전에는 입력과 은닉 상태에 곱해지는 가중치를 Wg로 별도로 표기했으나 이 그림에서는 Wx와 Wh로 나누어지게 됨
이렇게 나누어 계산하면 은닉 상태에 곱해지는 가중치 외에 절편이 별도로 필요하게 되어 작은 셀마다 하나씩 절편이 추가됨
즉,
Wr로 인한 출력 x 은닉 상태 (h) x 가중치 (Wg = Wh + Wx) 가 G셀에 입력되었으나
은닉 상태 (h) x 가중치 (Wh) x Wr로 인한 출력 x 가중치 (Wx) 가 G 셀에 입력됨
GRU 신경망 훈련하기
- GRU 신경망
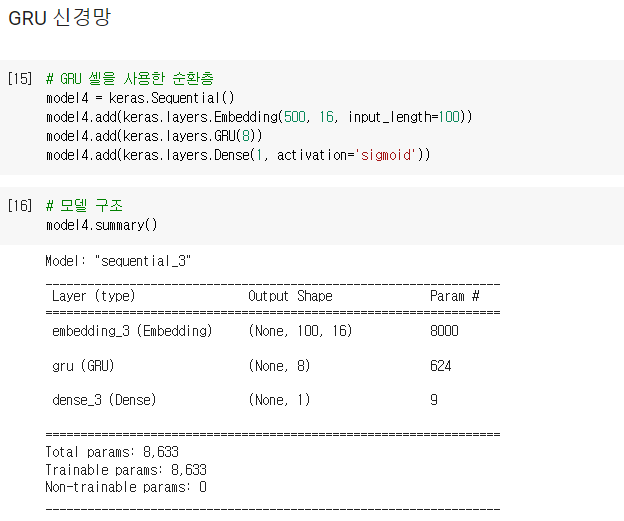
LSTM 클래스를 GRU 클래스로 바뀐 것 이외에는 이전 모델과 동일함
GRU 층의 모델 파라미터 개수를 계산해보면 GRU 셀에는 3개의 작은 셀이 있으므로
입력에 곱하는 가중치는 16 x 8 = 128개, 은닉 상태에 곱하는 가중치는 8 x 8 = 64개, 그리고 절편은 뉴런마다 하나씩이므로 8개
모두 더하면 128 + 64 + 8 = 200개이며 이런 작은 셀이 3개이므로 모두 600개
여기에 GRU 셀은 입력과 은닉 상태에 곱해지는 가중치를 Wg로 별도로 표현하는 것이 아닌, Wx와 Whfh 나누어 계산하므로
은닉 상태에 곱해지는 가중치 외에 절편이 별도 필요하므로 여기에 작은 셀마다 하나씩 절편이 추가되므로 8 x 3 = 24
그러므로 (16 x 8 + 8 x 8 + 8 + 8) x 3 = 624개의 모델 파라미터를 가짐
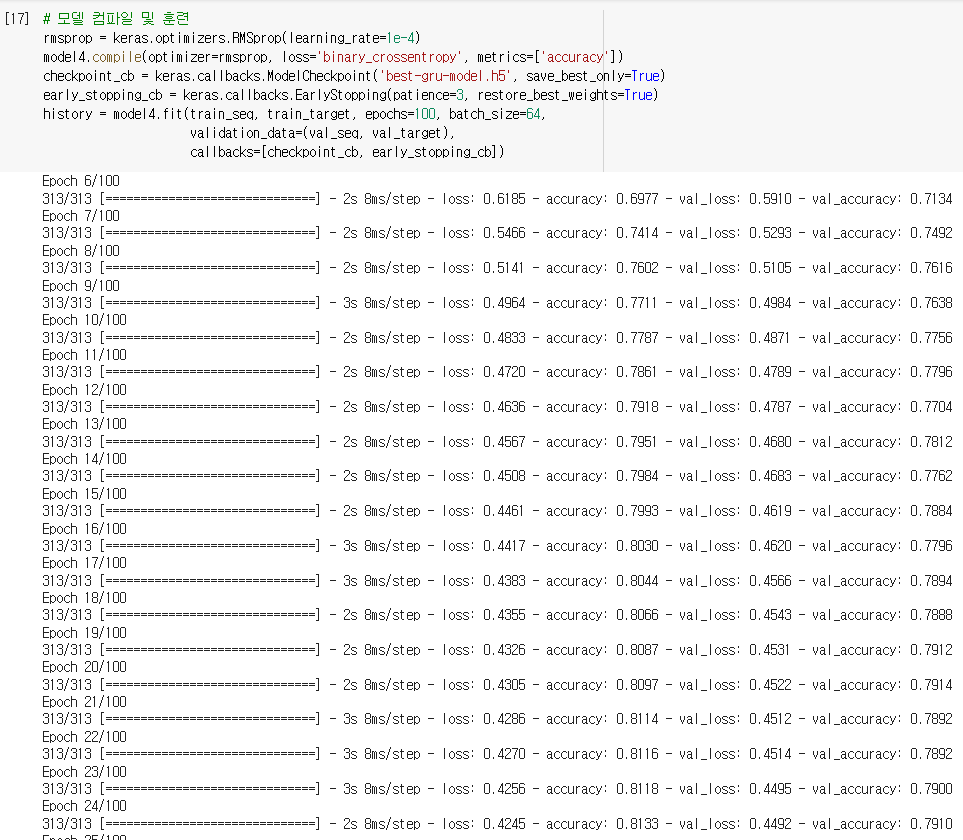
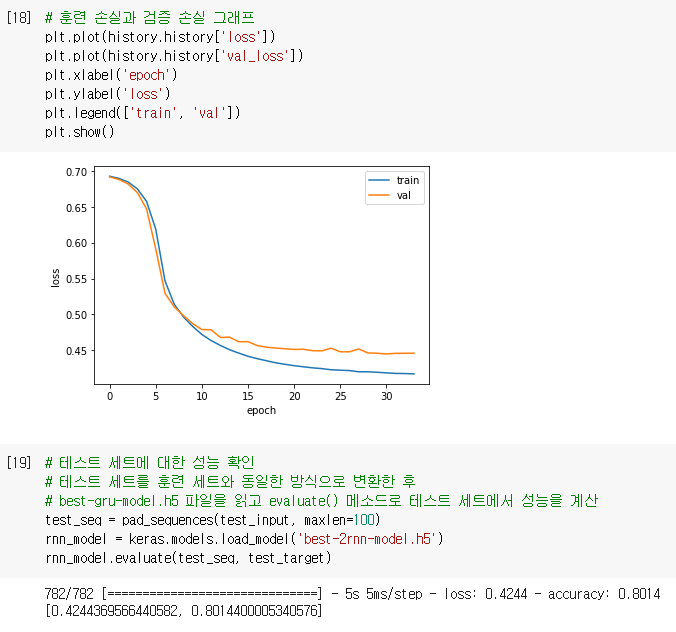
GRU 셀을 사용해 순환 신경망을 훈련하면 LSTM과 거의 비슷한 성능을 내며
이 모델의 손실을 그래프로 그려서 확인해보면 드롭아웃을 사용하지 않았기 때문에
이전보다 훈련 손실과 검증 손실 사이에 차이가 있지만 훈련 과정이 잘 수렴되고 있는 것을 확인할 수 있음
즉, GRU 셀은 LSTM보다 가중치가 적기 때문에 계산량이 적지만 LSTM 못지않은 좋은 성능을 냄
 012
012
'ML > 혼자 공부하는 머신러닝 + 딥러닝' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 - 목차 (0) | 2023.07.03 |
|---|---|
| [혼공머신] 09. 텍스트를 위한 인공 신경망 - 순환 신경망으로 IMDB 리뷰 분류하기 (0) | 2022.07.20 |
| [혼공머신] 09. 텍스트를 위한 인공 신경망 - 순차 데이터와 순환 신경망 (0) | 2022.07.19 |
| [혼공머신] 08. 이미지를 위한 인공 신경망 - 합성곱 신경망의 시각화 (0) | 2022.07.14 |
| [혼공머신] 08. 이미지를 위한 인공 신경망 - 합성곱 신경망을 사용한 이미지 분류 (0) | 2022.07.13 |